
過学習を防ぐドロップアウト徹底解説

AIを知りたい
先生、『Drop Out』って、一部の情報をわざと消すんですよね?どうして消すことで精度が上がるんですか?意味がわからないです。

AIエンジニア
いい質問ですね。わざと情報を消すのは、一部分だけを見て判断する癖をなくすためです。全体を見て判断する力をつけさせる訓練のようなものだと考えてください。
AIを知りたい
一部分だけを見て判断する癖…ですか?
AIエンジニア
例えば、猫の画像を認識させるとします。ひげだけを見て猫と判断する癖がついてしまうと、ひげがない猫を認識できなくなりますよね。一部分の情報がなくても猫と判断できるようにするために、わざと情報を消して学習させるのです。
Drop Outとは。
人工知能の用語で「間引き学習」というものがあります。これは、人工知能の学習中に、一部の繋がりをわざと使わずに学習を進めることで、学習しすぎるのを防ぎ、正確さを上げる方法です。特定の部分の出力を学習中にランダムにゼロにすることで、一部の情報が欠けていても正しく認識できるようにします。例えるなら、絵の一部が隠れていても全体像を把握できるように訓練するようなものです。これにより、絵の中の特定の部分の特徴ばかりに注目してしまうのを防ぎ、色々な変化にも対応できる強いモデルを作ることができます。学習が終わって実際に使う時には、全ての繋がりを使って、学習中に使わなかった箇所の割合を掛けて結果を調整します。間引き学習が高い性能を持つ理由は、複数のモデルを組み合わせる「集団学習」という方法に似ているためとも言われています。
ドロップアウトとは

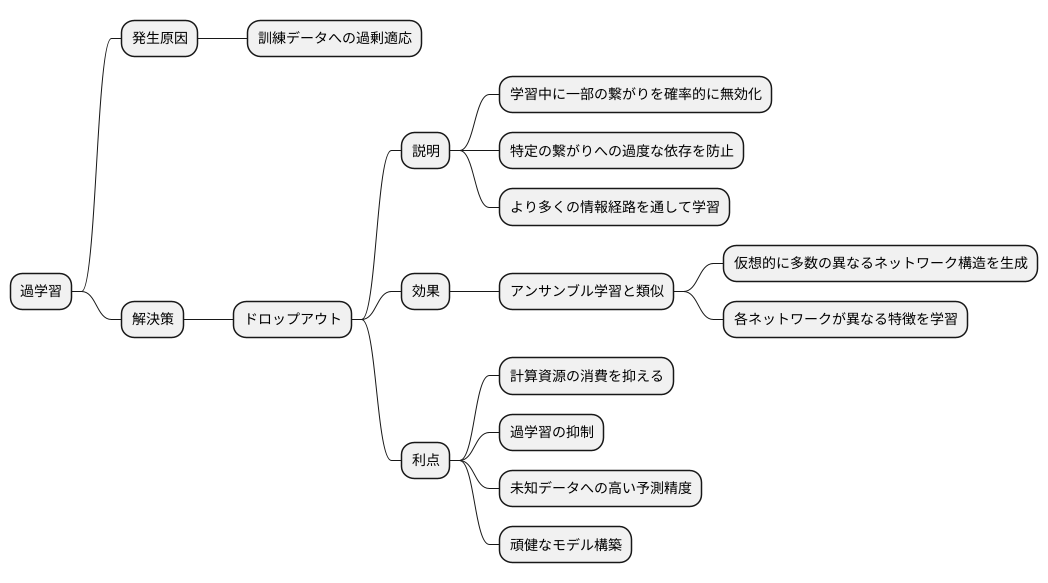
ドロップアウトは、複雑な計算を行う機械学習、特に多くの層を持つ深層学習において、学習済みモデルの性能を向上させるための技術です。深層学習では、モデルが学習に用いるデータに過度に適応してしまう「過学習」という問題がよく発生します。過学習とは、いわば「試験問題の答えだけを丸暗記してしまう」ような状態です。この状態では、試験問題と全く同じ問題が出れば満点を取ることができますが、少し問題が変化すると全く解けなくなってしまいます。同様に、過学習を起こした深層学習モデルは、学習に用いたデータには高い精度を示しますが、新しい未知のデータに対しては予測精度が落ちてしまいます。ドロップアウトは、この過学習を防ぐための有効な手段の一つです。
ドロップアウトは、学習の各段階で、幾つかの計算の部品を意図的に働かないようにするという、一見不思議な方法を取ります。計算の部品に当たるニューロンを、一定の確率でランダムに選び、一時的に活動を停止させるのです。停止したニューロンは、その時の学習には一切関与しません。これは、学習に用いるデータの一部を意図的に隠蔽することに似ています。一部の情報が欠けていても正しく答えを導き出せるように、モデルを訓練するのです。
ドロップアウトを用いることで、モデルは特定のニューロンに過度に依存するのを防ぎ、より多くのニューロンをバランス良く活用するようになります。全体像を把握する能力が向上し、結果として、未知のデータに対しても高い精度で予測できるようになります。これは、一部分が隠されていても全体像を把握できるように訓練された成果と言えるでしょう。ドロップアウトは、複雑なモデルをより賢く、より柔軟にするための、強力な技術なのです。
ドロップアウトの仕組み

抜き落とし法とは、人の脳神経系の仕組みをまねて作られた、計算学習の技です。この技は、たくさんの繋がった計算機が複雑な計算をする中で、一部の計算機をわざと休ませることで、計算の精度を高めることができます。
計算の訓練中は、繋がっている計算機の一部を、くじ引きのように選んで休ませます。休ませる計算機の割合は、あらかじめ決めておきます。休ませた計算機からは、計算結果が出力されません。ちょうど、計算の道筋が途中で途切れたかのようになります。
この「休ませる」作業は、計算を順方向に行うときだけでなく、計算結果を基に修正を行う逆方向のときにも、同じように行います。つまり、行きも帰りも同じ道筋が途切れます。
毎回異なる計算機を休ませることで、計算のたびに、計算機の繋がり方が変化します。これは、様々な道のりで計算を訓練するようなものです。特定の計算機に頼りきりになることを防ぎ、様々な状況に対応できる、より柔軟な計算の仕組みを作ることができます。
たくさんの異なる道筋で訓練された計算の仕組みは、未知のデータに対しても、より正確な結果を出せるようになります。これが、抜き落とし法によって計算の精度が向上する理由です。
この抜き落とし法は、計算の中間地点だけでなく、最初の入力部分にも使うことができます。しかし、最終結果を出す出力部分には使いません。最終結果を出す計算機を休ませてしまうと、結果が不安定になり、正しい答えを導き出せなくなるからです。
ドロップアウトの効果

学習を何度も繰り返すうちに、機械学習のモデルは訓練データに過剰に適応してしまうことがあります。これは過学習と呼ばれ、未知のデータに対する予測精度が低下する原因となります。この問題に対処するために、ドロップアウトという手法が広く用いられています。
ドロップアウトは、学習の過程で、一部の繋がりを確率的に無効化する技術です。例えるなら、神経細胞のネットワークの一部を一時的に休ませるようなものです。これにより、特定の繋がりに過度に依存することを防ぎ、より多くの情報経路を通して学習を進めることができます。
ドロップアウトは、複数のモデルを組み合わせるアンサンブル学習と似た効果をもたらします。アンサンブル学習では、それぞれ異なる特徴を学習した複数のモデルの予測結果を統合することで、より精度の高い予測を実現します。ドロップアウトは、学習のたびに異なる繋がりを無効化することで、仮想的に多数の異なるネットワーク構造を生成します。これらの仮想的なネットワークがそれぞれ異なる特徴を学習し、結果的にアンサンブル学習と同様の効果が得られるのです。
ドロップアウトを用いる利点は、計算の手間を増やさずに、アンサンブル学習の利点を得られることです。複数のモデルを個別に学習して組み合わせる必要がないため、計算資源の消費を抑えつつ、過学習を抑制し、未知のデータに対しても高い予測精度を維持する、頑健なモデルを構築できます。これにより、限られた資源でも効率的に高性能なモデルを開発することが可能になります。
ドロップアウトの適用例

情報の抜け落ちを人工的に作り出すことで、学習の過剰適合を防ぎ、様々な分野で成果をあげている手法である、ドロップアウトについて、具体的な適用例をいくつかご紹介いたします。
まず、画像認識の分野では、写真や絵といった画像データから、そこに写っているものや状況をコンピュータに理解させる技術が盛んに研究されています。この画像認識の分野において、畳み込みニューラルネットワークは重要な役割を担っています。このネットワークにドロップアウトを適用することで、画像に含まれる不要な情報やノイズの影響を受けにくくなり、より正確な認識が可能になります。例えば、手書き文字認識や物体検出といったタスクにおいて、ドロップアウトは認識精度向上に貢献しています。
次に、自然言語処理の分野では、人間が日常的に使っている言葉をコンピュータに理解させ、処理させる技術が研究されています。近年注目を集めている再帰型ニューラルネットワークやTransformerといったモデルにおいても、ドロップアウトは有効です。これらのモデルは、単語や文章といった系列データを扱う際に、文脈情報を効果的に捉えることができます。しかし、学習データに過剰に適合してしまうと、未知のデータに対する性能が低下する可能性があります。ドロップアウトを適用することで、この過剰適合を防ぎ、より汎用的な言語理解能力を獲得することができます。例えば、機械翻訳や文章要約といったタスクにおいて、ドロップアウトは性能向上に役立っています。
最後に、音声認識の分野では、人間の声をコンピュータに認識させ、文字データに変換する技術が実用化されています。音声データには、周囲の雑音や話者の発音の違いなど、様々なノイズが含まれているため、ノイズに強い認識モデルの構築が求められます。ドロップアウトは、このノイズに対する頑健性を高める上で効果的な手法です。音声認識モデルにドロップアウトを適用することで、ノイズの影響を軽減し、より正確な音声認識を実現することができます。
このようにドロップアウトは、様々な深層学習のタスクにおいて、モデルの性能向上に大きく貢献しています。そして、今後も様々な応用が期待されています。
| 分野 | 適用モデル | 効果 | 適用例 |
|---|---|---|---|
| 画像認識 | 畳み込みニューラルネットワーク | ノイズの影響軽減、正確な認識 | 手書き文字認識、物体検出 |
| 自然言語処理 | 再帰型ニューラルネットワーク、Transformer | 過剰適合の防止、汎用的な言語理解能力の向上 | 機械翻訳、文章要約 |
| 音声認識 | 音声認識モデル | ノイズに対する頑健性向上、正確な音声認識 | – |
ドロップアウト率の設定

学習をより効果的に行うための手法として、過学習を防ぐための仕組みであるドロップアウトがあります。このドロップアウトを適用する際に、どれだけの割合で神経細胞を休ませるかを決める必要があります。この割合のことをドロップアウト率といいます。ドロップアウト率は、学習の各段階において、働かないようにする神経細胞の割合を示しています。
一般的には、このドロップアウト率は0.1から0.5の間で設定されることが多いです。これは、全体の神経細胞の10%から50%を休ませるという意味です。しかし、最適なドロップアウト率は、扱う問題やデータの種類によって大きく変わるため、一概にどれが良いとは言えません。例えば、画像認識や音声認識など、扱うデータが複雑なタスクでは、高めのドロップアウト率が適している場合もあります。
ドロップアウト率が低い、つまり休ませる神経細胞が少ない場合は、過学習を防ぐ効果が小さくなります。逆に、ドロップアウト率が高い、つまり休ませる神経細胞が多い場合は、学習が不安定になり、思うように学習が進まない可能性があります。これは、学習に必要な情報が不足してしまうためと考えられます。
最適なドロップアウト率を見つけるためには、実際に試してみるしかありません。検証用のデータを使って、様々なドロップアウト率を試してみて、一番良い結果が得られる値を探す必要があります。例えば、交差検証といった手法を用いることで、様々なドロップアウト率を体系的に試し、最適な値を効率的に見つけることができます。この検証作業は、試行錯誤が必要となる重要な工程と言えるでしょう。
| ドロップアウト率 | 効果 | デメリット |
|---|---|---|
| 低い (0.1に近い) | 過学習防止効果が小さい | – |
| 高い (0.5に近い) | – | 学習が不安定になり、学習が進まない可能性がある |
| 最適な値 | 過学習を防ぎつつ、安定した学習が可能 | 問題やデータの種類によって異なるため、検証が必要 |
ドロップアウトと他の正則化手法との関係

機械学習において、学習済み模型が訓練データに過剰に適合してしまう過学習は、しばしば問題となります。この過学習を防ぐための手法の一つとして、ドロップアウトが広く知られています。ドロップアウトは、学習の過程で、神経細胞を確率的に無効化することで、過剰な適合を防ぐ技術です。しかし、ドロップアウト以外にも、過学習を抑制する様々な正則化手法が存在し、これらを組み合わせて用いることで、より効果的な学習が可能となります。
例えば、L1正則化とL2正則化は、模型の重みに制限を加えることで過学習を抑制する方法です。L1正則化は、重みの絶対値の和を小さくするように働き、不要な重みをゼロにする効果があります。一方、L2正則化は、重みの二乗和を小さくするように働き、重みが極端に大きくなることを防ぎます。これらの正則化手法は、ドロップアウトと併用することで、相乗効果を発揮することがあります。
また、早期終了も有効な正則化手法の一つです。早期終了は、検証データに対する精度が向上しなくなったり、むしろ低下し始めた時点で学習を打ち切ることで、過学習を防ぎます。学習を長く続けすぎると、訓練データに過剰に適合してしまい、未知のデータに対する性能が低下するからです。
ドロップアウトとこれらの正則化手法を組み合わせる場合、例えば、ドロップアウトとL2正則化を併用することで、よりロバストな模型を学習できる可能性があります。ドロップアウトは神経細胞の多様性を促し、L2正則化は重みの大きさを抑制するため、両者を組み合わせることで、過学習をより効果的に防ぐことができると考えられます。
しかし、最適な正則化手法の組み合わせは、扱う問題やデータの性質によって変化します。そのため、様々な手法を試し、実験的に最も効果的な組み合わせを見つけることが重要です。それぞれの正則化手法の特徴を理解し、適切に組み合わせることで、過学習を防ぎ、より汎化性能の高い模型を構築することが可能となります。
| 手法 | 説明 | 効果 |
|---|---|---|
| ドロップアウト | 学習中にランダムにニューロンを無効化 | 過学習抑制、ニューロンの多様性促進 |
| L1正則化 | 重みの絶対値の和を最小化 | 過学習抑制、不要な重みをゼロ化 |
| L2正則化 | 重みの二乗和を最小化 | 過学習抑制、重みが極端に大きくになることを防止 |
| 早期終了 | 検証データの精度が悪化し始めたら学習を停止 | 過学習抑制 |