
データ拡張:学習データ不足を解消する手法

AIを知りたい
先生、「データ拡張」ってどういう意味ですか?

AIエンジニア
いい質問だね。データ拡張とは、機械学習をする際に、データが少ない時に、人工的にデータを増やす技術のことだよ。 例えば、写真に少し回転を加えたり、明るさを変えたりすることで、元の写真とは少し違う新しい写真を作り出すことができるんだ。
AIを知りたい
なるほど。写真を変えることで、データが増えるんですね。でも、なぜそんなことをする必要があるんですか?
AIエンジニア
機械学習は、たくさんのデータを使って学習することで精度が上がるんだ。データが少ないと、うまく学習できないことがある。だから、データ拡張を使ってデータを増やすことで、学習の精度を向上させることができるんだよ。
Data Augmentationとは。
人工知能で使われる言葉「データ拡張」について説明します。データ拡張とは、深い学習に必要なデータの集まりが足りない時に、すでにあるデータを加工してデータの数を増やし、学習を十分にできるようにする技術のことです。
データ拡張とは

データ拡張とは、機械学習、とりわけ深層学習において、学習に用いるデータが足りない時に役立つ技術のことです。深層学習は多くのデータで学習させるほど性能が向上しますが、十分な量のデータを集めるのは容易ではありません。そこで、データ拡張を用いて少ないデータから人工的に多くのデータを作り出し、学習データの不足を補うのです。
データ拡張の基本的な考え方は、既存のデータに様々な変換を加えて、似たような新しいデータを作り出すことです。例えば、画像認識の分野を考えてみましょう。一枚の猫の画像があるとします。この画像を少し回転させたり、左右反転させたり、拡大縮小したりすることで、元の画像とは少しだけ異なる、しかし猫であることは変わらない複数の画像を生成できます。これらはコンピュータにとっては別の画像として認識されるため、少ないデータから多くの学習データを生成できるのです。
画像認識以外にも、自然言語処理や音声認識など、様々な分野でデータ拡張は活用されています。例えば音声認識であれば、音声を少し高くしたり低くしたり、速くしたり遅くしたりすることで、データ拡張を行うことができます。このようにデータ拡張は、データを集める手間や費用を減らしつつ、学習に使えるデータの量を増やし、モデルの性能向上に大きく貢献する大変効果的な手法と言えるでしょう。
データ拡張を使うことで、モデルが特定のデータのみに過剰に適応してしまう「過学習」を防ぎ、様々な状況に対応できる汎化性能の高いモデルを構築することが可能になります。つまり、初めて見るデータに対しても、正しく予測できる能力を高めることができるのです。これは、人工知能モデルの実用化において非常に重要な要素となります。
| 分野 | データ拡張の方法 | 効果 |
|---|---|---|
| 機械学習(特に深層学習) | 学習データが少ない時に、既存データに変換を加えて人工的にデータ量を増やす | 学習データ不足の解消、モデル性能向上 |
| 画像認識 | 回転、左右反転、拡大縮小など | 少ない画像から多くの学習データを生成 |
| 自然言語処理 | 同義語置換、ランダム挿入、ランダム削除など | 文のバリエーションを増やし、モデルの頑健性を向上 |
| 音声認識 | 音声の高低、速度変更など | 音声データのバリエーションを増やし、認識精度向上 |
| 全般 | 過学習の防止、汎化性能の向上 | 初めて見るデータに対しても正しく予測できる能力を高める |
画像認識における応用

物の形を捉える技術、いわゆる画像認識は、様々な場面で使われています。中でも、学習に使う画像データを人工的に増やす技術、データ拡張は、認識の精度を高める上で欠かせません。例えば、猫を見分ける仕組みを作る場合を考えてみましょう。
データ拡張を使うと、一枚の猫の画像から、様々なバリエーションの画像を作ることができます。元の画像を少し回転させたり、左右を反転させたり、明るさを変えたりすることで、色々な角度や明るさ条件での猫の画像を生成できるのです。このようにして作られたたくさんの画像を学習に使うことで、特定の条件だけでなく、どんな猫の画像でも見分けられる仕組みを作ることができます。これは、まるで色々な猫をたくさん見て学習する人間のようです。
データ拡張には、もう一つ重要な役割があります。それは、仕組みが学習データに偏ってしまうことを防ぐことです。学習データに偏ってしまうと、学習に使った画像には正しく反応できても、それ以外の画像にはうまく反応できない、融通の利かない仕組みになってしまいます。これは、特定の猫ばかり見て学習し、他の猫を見分けられないのと同じです。データ拡張によって画像のバリエーションを増やすことで、特定の画像に偏ることなく、様々な画像に対応できる、より柔軟な仕組みを作ることができるのです。つまり、初めて見る猫でも、きちんと猫だと認識できるようになるということです。
このように、データ拡張は画像認識の精度を高め、より実用的な仕組みを作る上で、とても重要な技術なのです。
| データ拡張の役割 | 具体的な処理 | 効果 |
|---|---|---|
| 認識精度の向上 | 回転、反転、明るさ変更など | 様々な角度や明るさ条件に対応できる |
| 学習データへの偏りを防ぐ | 画像のバリエーションを増やす | 特定の画像に偏ることなく、様々な画像に対応できる |
自然言語処理における応用

言葉に関する処理を機械にさせる技術、いわゆる自然言語処理においても、学習に使う材料を増やす技術、データ拡張はとても大切な役割を担っています。データ拡張によって、限られた材料から多くの学びを得ることができ、処理の正確さを大きく向上させることが可能になります。
例えば、文章の種類を機械に判断させる文章分類の作業を考えてみましょう。ある文章が経済に関するものか、スポーツに関するものかなどを機械に判断させるためには、多くの学習材料が必要です。しかし、材料を集めるのは大変な作業です。そこで、データ拡張を使って少ない材料から多くの学習材料を作り出すのです。具体的には、文章の中に含まれる言葉と同じ意味を持つ別の言葉を置き換えたり、言葉の順番を少し入れ替えたりすることで、新しい文章を作り出します。「今日は晴天です」という文章を、「本日は快晴です」と言い換えるといった具合です。このように少し変化を加えることで、もとの文章とほとんど同じ意味でありながら、異なる表現の文章を作り出すことができます。これにより、機械は様々な言い回しを学習し、より正確に文章の種類を判断できるようになります。
また、言葉を別の言葉に置き換える機械翻訳の作業でも、データ拡張は力を発揮します。例えば、日本語を英語に翻訳する場合を考えてみましょう。この場合も、多くの日本語の文章と、それに対応する英語の文章が必要です。しかし、翻訳の学習材料を集めるのは簡単ではありません。そこで、データ拡張を使って日本語の文章を少しだけ変え、それに対応する英語の文章も少しだけ変えることで、学習材料を増やすことができます。「私はりんごを食べます」を「私は果物のりんごを食べます」に変え、対応する英語も少し変える、といった具合です。このようにすることで、限られた翻訳データから多くの学習データを作り出し、翻訳の精度を高めることができます。
このように、自然言語処理の様々な場面で、データ拡張は重要な役割を担い、処理能力の向上に貢献しています。今後、より高度なデータ拡張技術が開発されることで、自然言語処理はさらに発展していくことが期待されます。
| タスク | データ拡張の方法 | 効果 |
|---|---|---|
| 文章分類 (例: 経済、スポーツなど) | 同義語置換、語順入れ替え (例: 「今日は晴天です」→「本日は快晴です」) | 様々な言い回しを学習し、正確な分類が可能になる |
| 機械翻訳 (例: 日本語→英語) | 原文と訳文を両方少し変更 (例: 「私はりんごを食べます」と対応する英語→「私は果物のりんごを食べます」と対応する少し変更された英語) | 限られたデータから多くの学習データを作り出し、翻訳精度を高める |
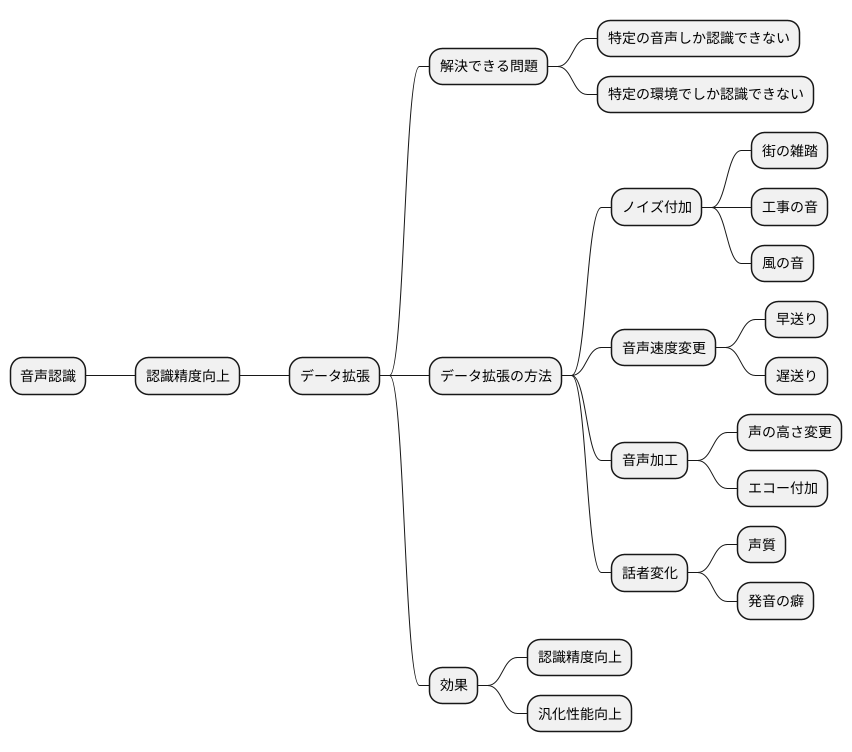
音声認識における応用

音声認識は、人間の声を機械が理解するための技術であり、私たちの生活で increasingly 重要性を増しています。音声検索や音声入力、自動翻訳など、様々な場面で活用されており、より高い認識精度が求められています。この認識精度向上に大きく貢献するのがデータ拡張という手法です。
データ拡張とは、限られた音声データから人工的に多様なデータを生成する技術です。音声データが少ないと、特定の音声しか認識できない、特定の環境でしか認識できないといった問題が発生しやすいです。データ拡張によって音声データのバリエーションを増やすことで、この問題を解決し、様々な状況に対応できる、より頑健な音声認識モデルを作ることができます。
音声データに様々な種類のノイズを加えることが、データ拡張の基本的な方法の一つです。例えば、街の雑踏や工事の音、風の音などを加えることで、騒がしい環境でも正確に音声を認識できるようになります。また、音声の再生速度を速めたり遅めたりすることで、話す速度が異なる人の音声にも対応できるようになります。さらに、声の高さを変えたり、エコーを加えたりすることで、より多様な音声データを生成することが可能です。
話者の声質や発音の癖を人工的に変化させることも有効な手段です。同じ言葉でも、人によって発音やイントネーションが異なるため、多様な声質のデータで学習することで、より多くの人に対応できる音声認識モデルを構築できます。
このように、データ拡張は、限られたデータから多様なデータを生成し、音声認識モデルの認識精度や汎化性能を向上させるために不可欠な技術です。音声認識技術の進化に伴い、データ拡張技術も進化を続けており、今後の更なる発展が期待される重要な分野と言えるでしょう。
データ拡張の注意点

データ拡張は、限られた学習データからより多くのデータを人工的に作り出すことで、機械学習モデルの精度向上に役立つ強力な手法です。しかし、その効果を最大限に発揮するためには、いくつかの注意点に留意する必要があります。何よりも大切なのは、データの本来持つ意味や特徴を損なわないようにすることです。
例えば、手書き数字の画像認識を想定してみましょう。画像を左右反転させる変換は、数字の「6」と「9」を見分ける上では問題となりえます。左右反転によって数字の意味が変わってしまうからです。同様に、数字「2」を上下反転させると、全く異なる意味を持つ記号になってしまう可能性があります。このように、データの性質に応じて、適用する変換が適切かどうかを慎重に検討する必要があります。
また、変換によってデータの質が低下することも避けるべきです。画像データであれば、過剰なノイズを加えたり、画像の解像度を極端に下げたりすると、かえってモデルの学習に悪影響を及ぼす可能性があります。これは、ノイズやぼやけによって重要な特徴が失われ、モデルが正しい判断をするのが難しくなるためです。音声データの場合も同様に、ノイズの付加や音質の劣化は、認識精度を下げる要因となります。
データ拡張を行う際は、データの種類や特性を深く理解し、それに適した変換方法を選ぶことが重要です。画像データであれば、回転、平行移動、拡大縮小などの変換が有効です。一方、音声データであれば、ピッチシフトや時間伸縮、ノイズ付加などが考えられます。これらの変換は、それぞれパラメータを調整することで、データ拡張の効果を細かく制御することができます。例えば、回転角度を小さく設定することで、大きな変化を避け、データの本来の意味を保持しやすくなります。
適切なデータ拡張は、モデルの汎化性能を高め、未知データに対しても正確な予測を可能にします。しかし、変換方法を誤ると、逆効果になる可能性もあるため、データの特性を理解し、慎重に適用することが重要です。
| データの種類 | 適切な変換例 | 不適切な変換例 | 変換時の注意点 |
|---|---|---|---|
| 手書き数字画像 | 回転、平行移動、拡大縮小 | 左右反転(6と9)、上下反転(2) | 数字の意味が変わらない変換 |
| 画像データ全般 | 回転、平行移動、拡大縮小 | 過剰なノイズ付加、極端な解像度低下 | 重要な特徴を失わない変換、データの質を低下させない |
| 音声データ | ピッチシフト、時間伸縮、ノイズ付加 | 過剰なノイズ付加、音質劣化 | 認識精度を下げない変換 |
今後の展望

今後のデータ増やし技術の進展について考えてみましょう。近年の機械学習、特に深い学びの分野では、学習に使う情報の不足が大きな課題となっています。そこで、限られた情報からより多くの学びの材料を作り出す技術、いわゆるデータ増やし技術が重要性を増しています。
これまでのデータ増やし技術では、画像を回転させたり、反転させたりといった単純な方法が主でした。しかし、これらの方法では、作られる情報の種類も限られ、学びの効果を高めるには不十分な場合もありました。そこで、近年注目されているのが、まるで生きているかのような新たな情報を作る技術です。これは、互いに競い合う二つの仕組みを使うことで、より本物に近い、多様な情報を作ることができます。例えば、手書きの文字を模倣する場合、この技術を使うことで、様々な書き方で書かれた、より自然な文字を作り出すことができます。
さらに、情報の特性を自動的に見極め、最適な変換を施す技術の研究も進んでいます。従来の方法では、人間がそれぞれの情報に合わせて変換方法を調整する必要がありました。しかし、この自動化技術により、より効率的に、かつ効果的にデータ増やしを行うことが可能になります。
これらの技術の進展は、情報不足に悩む様々な分野で革新をもたらす可能性を秘めています。例えば、医療分野では、少ない症例データから多くの学びの材料を作り出すことで、より精度の高い診断が可能になるかもしれません。また、製造業では、製品の欠陥を検出するシステムの精度向上に役立つことが期待されます。このように、データ増やし技術は、今後ますます重要な役割を果たし、様々な分野で応用されていくと考えられます。
| データ増やし技術の進展 | 詳細 |
|---|---|
| 従来の方法 | 画像の回転、反転など単純な変換。生成されるデータの種類が限られ、学習効果向上に不十分な場合も。 |
| 近年の動向 | まるで生きているかのような新たな情報を作る技術。互いに競い合う二つの仕組みを使い、本物に近い多様なデータ生成。例:手書き文字の様々な書き方の模倣。 |
| 今後の展望 | 情報の特性を自動的に見極め、最適な変換を施す技術。人間による調整が不要になり、効率的かつ効果的なデータ増やしが可能に。 |
| 応用分野 | 医療(高精度診断)、製造業(製品欠陥検出)など、データ不足に悩む様々な分野での革新。 |