音声認識の立役者:CTCを学ぶ

AIを知りたい
先生、『接続時系列分類』って難しいですね。音声の認識で、入力と出力が一致しないときをなんとかする手法ですよね?

AIエンジニア
そうだね。『接続時系列分類』は、音声データと文字データの長さが違う問題を解決する手法だよ。例えば、『こんにちは』と言うとき、音声データの長さは声の高さや話す速さで変わるけど、文字データは『こんにちは』の5文字で固定だよね。この違いを埋めるのが『接続時系列分類』の役割なんだ。
AIを知りたい
なるほど。でも、具体的にどうするんですか?
AIエンジニア
『こんにちは』を『こんんにちは』や『こ_んに_ちは』と認識しても正解とするように学習させるんだ。余分な音や空白を許容することで、音声データの長さと文字データの長さのずれを吸収するんだよ。
CTCとは。
音声認識などで使われるAI技術の用語「CTC」(接続時系列分類)について説明します。RNNという技術では、入力データの数と出力データの数は必ず一致します。しかし、音声を扱う場合は、入力された音声データの数と、出力するべき音の数(音素)が、必ずしも一致するとは限りません。この違いを埋める方法がCTCです。例えば、「hello」という言葉の場合、「heello」や「he_llo」、「helloo」といった出力も正解として扱われます。
つながりの時系列分類とは

私たちが話す言葉を機械に理解させる技術、音声認識。この技術を支える重要な仕組みの一つに、つながりの時系列分類(CTC)があります。このCTCは、音声と文字の長さが違うという問題をうまく解決してくれるのです。音声は時間的に連続したデータである一方、文字は飛び飛びの記号です。例えば、「こんにちは」という言葉を発すると、実際の音声の長さは「こんにちは」の文字数よりもずっと長く、また人によって発音の長さや速さも違います。従来の音声認識技術では、音声データと文字データを一つずつ対応させる必要がありました。そのため、音声のどの部分がどの文字に対応するのかを事前に細かく指定しなければならず、大変な手間がかかっていました。
しかし、CTCはこの対応付けの手間を省き、音声認識の精度を大きく向上させました。CTCは、音声データの中のどの部分がどの文字に対応するのかを直接指定するのではなく、音声データ全体からどのような文字列が考えられるかを確率的に計算します。例えば、「こんにちは」と発音した音声データに対して、CTCは「こんんにちは」や「こんにちわー」など、様々な候補を考え、それぞれの候補がどれくらい可能性が高いかを計算します。そして、最も可能性の高い候補を認識結果として出力します。
このようにCTCは、音声データと文字データの長さが違っても、両者の関係性を学習することで、音声から最も適切な文字列を導き出すことができます。そのため、音声認識だけでなく、手書き文字認識など、時系列データと記号列の対応付けが必要な様々な場面で活用されています。CTCによって、機械は私たちの言葉をより正確に理解できるようになり、私たちの生活はより便利で豊かになるでしょう。
| 項目 | 説明 |
|---|---|
| つながりの時系列分類(CTC) | 音声と文字の長さが違う問題を解決する音声認識技術の重要な仕組み。音声データ全体からどのような文字列が考えられるかを確率的に計算し、最も可能性の高い候補を認識結果として出力する。 |
| 従来の音声認識技術 | 音声データと文字データを一つずつ対応させる必要があり、音声のどの部分がどの文字に対応するのかを事前に細かく指定しなければならなかった。 |
| CTCのメリット | 音声データと文字データの対応付けの手間を省き、音声認識の精度を向上させる。 |
| CTCの活用例 | 音声認識、手書き文字認識など、時系列データと記号列の対応付けが必要な場面。 |
従来手法との違い

これまでの音声認識のやり方では、音の情報と文字情報の長さを揃える必要がありました。例えば、「こんにちは」という音声があったとして、それを「こん」、「に」、「ち」、「は」という4つの音の断片に分け、それぞれの断片がどの文字に対応するのかを事前に決めておく必要があったのです。この作業は、音声を細かく分析し、それぞれの音の特徴を捉え、文字との対応付けを手作業で行う必要があり、非常に手間と時間のかかる作業でした。
一方、CTCと呼ばれる新しい手法では、音の情報と文字情報の長さが違っていても問題ありません。「こんにちは」という音声全体を一度に解析し、「こ」、「ん」、「に」、「ち」、「は」という文字列を見つけ出すことができるのです。これは、前もって音の断片と文字の対応付けを指定する必要がないということを意味し、音声認識システムを作る手間を大幅に減らすことができました。
さらに、CTCにはもう一つ大きな利点があります。それは、音声の時間的な変化に対応できるということです。例えば、人が話す速さは常に一定ではありません。ゆっくり話すこともあれば、早く話すこともあります。従来の手法では、このような時間的な変化に対応するのが難しく、認識精度が低下することがありました。しかし、CTCは音声の時間的な変化を柔軟に捉えることができるため、より自然で正確な音声認識が可能になるのです。これにより、これまで以上に実用的な音声認識システムの開発が可能になりました。
| 手法 | 音と文字の情報の長さ | 音の断片と文字の対応付け | 時間変化への対応 | メリット |
|---|---|---|---|---|
| 従来の手法 | 一致させる必要あり | 事前に手作業で指定 | 苦手(認識精度低下) | – |
| CTC | 一致させる必要なし | 自動で判別 | 得意 |
|
仕組みを分かりやすく

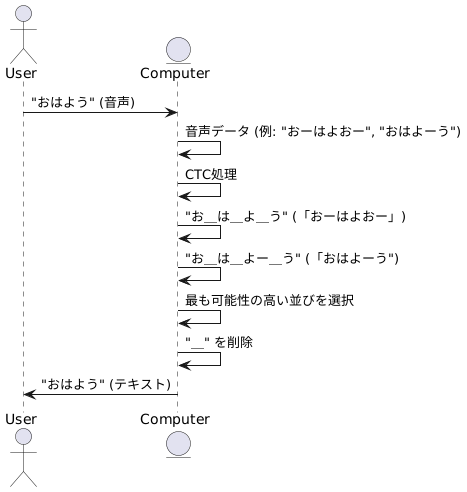
音声認識の仕組み、特にCTC(接続時系列分類)の仕組みについて、分かりやすく説明します。「おはよう」という言葉を入力した時のコンピュータの働きを例に考えてみましょう。
人が「おはよう」と話すと、コンピュータはマイクを通して音声を受け取ります。しかし、この音声データは「おはよう」と完全に一致するわけではありません。例えば、「おーはよおー」のように音が伸びたり、「おはよーう」のように音が短くなったり、人によって発音の長さや速さが違います。コンピュータはこのように様々な長さの音声データとして認識します。
そこで、CTCはこれらの音声データから「おはよう」という文字列を正しく出力するために、特別な記号「_」を使います。この記号は、発音はされているものの、文字に対応しない音声を表します。空白のようなものです。
例えば、「おーはよおー」という音声データは「お_は_よ_う」と表現されます。伸ばされている「おー」や「よー」の部分に「_」が挿入され、「お」「は」「よ」「う」のそれぞれの発音がどこでされているかを明確にしています。同様に、「おはよーう」は「お_は_よー_う」と表現されます。
CTCはこのように「_」を使って様々な表現を作り出し、その中から最も可能性の高い並びを選びます。そして、最後に「_」を取り除くことで、「おはよう」という文字列を出力します。
このように、CTCは入力された音声データの長さと出力される文字列の長さが異なっていても、特別な記号「_」を用いることで、正確に文字列に変換することを可能にしています。これは音声認識において非常に重要な技術です。
活用事例

音声をつづりに置き換える技術であるシーティーシーは、様々な場面で役立っており、私たちの暮らしを便利にしています。
まず、家庭では、話しかけるだけで操作できる機器で活躍しています。例えば、話しかけた言葉を理解し、音楽を再生したり、照明を調整したりする機器には、シーティーシーが欠かせません。私たちの声を正確に理解し、適切な動作をするために、この技術が重要な役割を担っています。
また、仕事で文章を作成する際にも、シーティーシーは役立ちます。音声入力で文章を作成する機能は、キーボードを使わずに、話すだけで文章を作成できるため、作業効率を向上させることができます。会議の内容を記録したり、長文の文章を作成したりする際に、大変便利です。さらに、外国語を学ぶ際にも、発音を音声認識して正誤判定を行うことで、学習効果を高めることができます。
さらに、移動の際にも、シーティーシーは活躍しています。自動車を運転中に、音声でカーナビゲーションを操作したり、電話をかけたりすることができます。画面操作をすることなく、音声だけで様々な操作ができるため、安全な運転を支援します。また、公共交通機関の案内放送や、駅構内でのアナウンスにも、シーティーシーが活用されています。より聞き取りやすいアナウンスを実現することで、利用者の利便性を向上させています。
このように、シーティーシーは、家庭、仕事、移動など、様々な場面で私たちの生活をより豊かに、便利にしています。今後、さらに技術が発展していくことで、さらに多くの分野での活用が期待されます。
| 場面 | 活用例 | メリット |
|---|---|---|
| 家庭 | 音声操作機器(音楽再生、照明調整など) | 話しかけるだけで操作が可能、利便性向上 |
| 仕事 | 音声入力による文章作成、会議記録、外国語学習 | 作業効率向上、キーボード操作不要、発音の正誤判定 |
| 移動 | カーナビゲーションの音声操作、ハンズフリー通話、公共交通機関の案内放送 | 安全運転支援、画面操作不要、聞き取りやすいアナウンス |
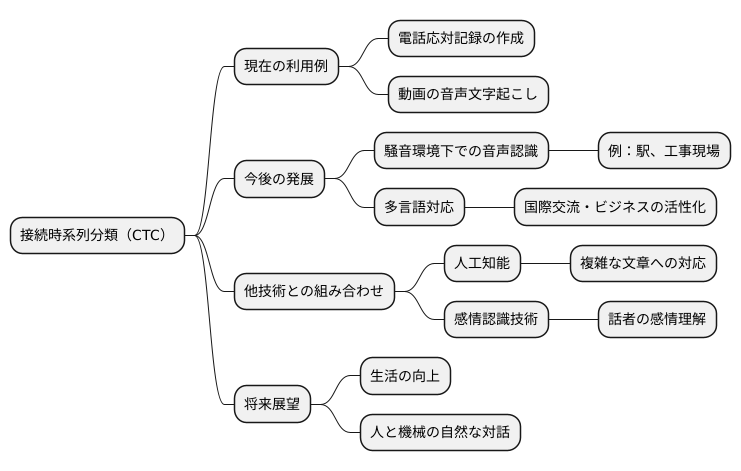
今後の展望

音声から文字を起こす技術、接続時系列分類(シーティーシー)は、既に様々な場面で使われています。電話での応対記録の作成や、動画の音声から文字起こしをするサービスなど、私たちの暮らしを便利にする技術です。しかし、シーティーシーの進歩はこれで終わりではありません。今後、さらに発展していく可能性を秘めています。特に、周囲が騒がしい場所でも正確に音声を認識することや、様々な国の言葉を理解できるようにすることが、今後の課題です。
騒がしい場所での音声認識は、周囲の雑音に邪魔されずに、話している人の声を正確に聞き取ることが重要です。例えば、駅や工事現場など、騒音が大きい場所でも、正確に音声認識ができれば、様々な作業がよりスムーズに行えるようになります。また、多言語対応の音声認識は、世界中の人々がより簡単にコミュニケーションをとれるようにするために不可欠です。異なる言語を話す人々が、お互いの言葉を理解し合えるようになれば、国際的な交流やビジネスがより活発になるでしょう。
シーティーシーを他の技術と組み合わせることで、さらに高度な音声認識システムを構築することも期待されています。例えば、人工知能による学習機能と組み合わせることで、より複雑な文章や言い回しにも対応できるようになるでしょう。また、感情認識技術と組み合わせることで、話している人の感情を理解する音声認識システムも開発できるかもしれません。
シーティーシーは、音声認識技術の中心となる技術として、これからも進化を続け、私たちの生活をより豊かにしていくと考えられます。音声認識技術の進歩は、人と機械との対話をより自然でスムーズなものにし、私たちの生活に大きな変化をもたらす可能性を秘めています。シーティーシーは、その進化を支える重要な技術として、今後も注目を集めていくことでしょう。