
画像認識精度向上のためのランダム消去

AIを知りたい
先生、『ランダムイレイズ』ってデータ拡張の手法の一つですよね?どんなものかよくわからないのですが、教えていただけますか?

AIエンジニア
はい、ランダムイレイズは画像に四角形で一部を隠す手法です。隠す四角形の大きさと、隠す時に使う色はランダムに決めます。例えるなら、写真の一部に白い四角や黒い四角をランダムな大きさで貼り付けるようなものです。
AIを知りたい
なるほど。隠してしまうと、大事な情報が消えてしまう気がしますが、どうなのでしょうか?
AIエンジニア
確かに、隠すことで学習に必要な情報が消えてしまう可能性はあります。しかし、ランダムに隠すことで、まるでノイズを加えたような効果が生まれ、結果として学習の精度が上がることがあります。隠すことで、手前の物が奥の物を隠してしまう状況を学習しやすくしたり、過学習を防ぐ効果も期待できます。
Random Erasingとは。
人工知能で使われる『ランダムイレイズ』という用語について説明します。ランダムイレイズは、データ拡張(データふやし)の方法の一つです。この方法では、画像の一部分を四角形で隠します。隠す四角の大きさはランダム(でたらめ)に決まり、隠された部分の色も0から255までのランダムな値になります。この方法を使うと、過学習(同じようなデータばかり学習してしまうこと)を減らしたり、手前のものが奥のものを隠してしまう影響を少なくしたりできます。ランダムイレイズは、カットアウトという方法と同じように、学習に必要な情報を削ってしまうため、効率が悪い面もあります。しかし、隠す部分がランダムに決まるので、ノイズ(雑音)のような働きをして、学習に良い影響を与えることもあります。
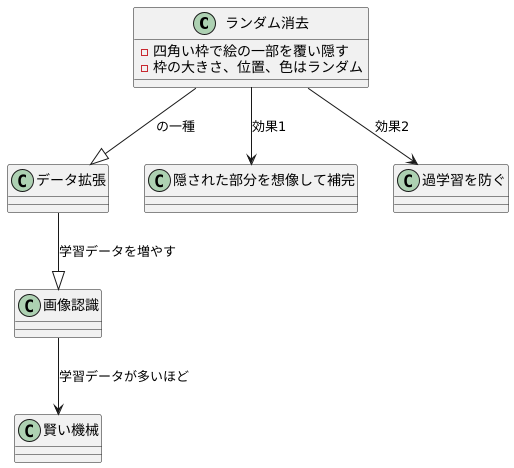
ランダム消去とは

物の姿形を機械に教える画像認識では、学習に使う絵の数が多ければ多いほど、機械は賢くなります。しかし、たくさんの絵を集めるのは大変な作業です。そこで、少ない絵から人工的に新しい絵を作り出す技術が生まれました。これをデータ拡張と言います。ランダム消去はこのデータ拡張の一つで、まるでいたずら書きのように絵の一部を塗りつぶすことで、新しい絵を作り出します。
具体的には、四角い枠で絵の一部を覆い隠します。この四角の大きさや位置は毎回ランダム、つまり偶然に決められます。隠す時に使う色も、毎回変わります。そのため、同じ絵であっても、何度もランダム消去を繰り返すと、毎回異なる部分が異なる色で塗りつぶされ、たくさんの違った絵ができあがります。
一見すると、絵を塗りつぶす行為は、絵を壊しているように思えます。しかし、この一見破壊的な行為が、画像認識の学習には大きな効果をもたらします。なぜなら、一部が隠された絵を学習することで、機械は隠された部分を想像して補完する能力を身につけます。例えば、猫の絵の顔が隠されていても、耳や体を見て猫だと判断できるようになるのです。
また、ランダム消去は過学習を防ぐ効果もあります。過学習とは、機械が学習用の絵に特化しすぎてしまい、新しい絵を正しく認識できなくなる現象です。ランダム消去によって絵の一部を変化させることで、機械は特定の絵に過度に適応することを防ぎ、より汎用的な認識能力を獲得できます。つまり、様々なバリエーションの絵を学習することで、見たことのない新しい絵にも対応できるようになるのです。
過学習への対処

機械学習において、学習済みの模型が訓練に使った資料の特徴を細部まで覚え込みすぎて、新しい資料に対してうまく対応できない場合があります。これを過学習と言います。過学習は、いわば試験対策で過去問を丸暗記したものの、出題形式が変わると全く解けなくなってしまう状態です。この問題に対処する有効な手段の一つに、ランダム消去があります。
ランダム消去とは、学習に使う画像の一部をわざと欠損させる技術です。ちょうど、パズルのピースをいくつか取り除くようなものです。模型は、完全な絵を見ることができない状態で学習を進めることになります。一見非効率的に思えるかもしれませんが、この欠損を補おうと試行錯誤することで、模型は画像の細部ではなく、本質的な特徴を捉えることを学びます。例えば、猫の画像の一部が隠れていても、耳や目、尻尾といった特徴から「猫」だと判断できるようになるのです。
ランダム消去を用いない場合、模型は訓練資料に含まれる些細な模様や背景まで記憶してしまい、それが「正解」の一部だと誤解する可能性があります。新しい資料に同じ模様や背景がなければ、模型は戸惑い、誤った判断を下すかもしれません。しかし、ランダム消去によって部分的な情報欠落に慣れることで、模型はより柔軟に対応できるようになり、未知の資料に対しても高い精度で予測できるようになります。これは、一部分が隠れていても全体像を把握する能力、すなわち頑健性と汎化性能の向上に繋がります。
このように、ランダム消去は、模型が本質を見抜く目を養うための、効果的な学習方法と言えるでしょう。
遮蔽への対応

私たちの身の回りでは、物が他の物で隠れてしまうことがよくあります。例えば、木が電柱を隠したり、人が看板を隠したりする様子を想像してみてください。このような現象を遮蔽と言います。遮蔽はコンピュータビジョンにおいて大きな課題となっており、隠された部分をどのように認識し、全体像を把握するかという点が重要です。
この遮蔽問題に対応するために、ランダム消去という手法が用いられます。ランダム消去とは、学習データとなる画像の一部分をランダムに消す技術のことです。まるで遮蔽されたかのように画像の一部を意図的に隠すことで、隠れた部分の情報がなくても、何が写っているかを正しく認識できるようにモデルを訓練します。
ランダム消去を用いることで、モデルは部分的に隠された情報から全体像を推測する能力を身につけます。例えば、木の幹の一部が隠れていても、残りの幹や枝、葉などの情報から、それが木であると推測できるようになります。人が看板の一部を隠していても、看板の色や形、残りの文字などから、看板に何が書いてあるかを推測できるようになります。
このように、ランダム消去は、隠された部分を推測する能力を向上させ、遮蔽への対応力を強化します。現実世界では、遮蔽は避けられない現象です。ランダム消去による学習を通して、モデルは現実世界で起こりうる様々な遮蔽状況に対応できるようになり、より正確な認識が可能となります。これにより、自動運転やロボット制御、画像検索など、様々な分野でより信頼性の高いシステムを構築できるようになります。
類似手法との比較

画像認識の分野では、学習データに様々な変化を加えることで、モデルの頑健性を高める手法が広く使われています。その一つとして、画像の一部を意図的に変化させる方法があります。この手法には様々な種類がありますが、ここでは「ランダム消去」という手法と、よく似た手法である「カットアウト」を比べてみましょう。
カットアウトは、画像の中から四角い領域をランダムに選び、その部分を事前に決めた一定の色で塗りつぶす手法です。例えば、黒や灰色で塗りつぶすことが多いです。一方、ランダム消去は、カットアウトと同様に四角い領域をランダムに選びますが、その部分を塗りつぶすのではなく、領域内のそれぞれの画素にランダムな値を割り当てます。つまり、塗りつぶす色の濃淡や色合い自体もランダムに変化するということです。
この違いが、二つの手法で生成される画像の多様性に影響を与えます。カットアウトでは、切り抜かれた領域は常に同じ色で塗りつぶされるため、生成される画像のバリエーションは限られます。しかし、ランダム消去では、切り抜かれた領域の色自体もランダムに変化するため、より多様な画像を生成することが可能です。これは、モデルが様々な変化に対応できるようになるため、結果としてモデルの性能向上につながると期待できます。
ランダム消去は、一見すると画像から情報を削ってしまうため、学習にとって非効率的に見えるかもしれません。カットアウトも同様に、画像情報の一部を欠損させるため、同じように非効率に思えるかもしれません。しかし、ランダム消去は、画素値をランダムに変化させることで、画像にノイズを加える効果も持ち合わせています。これは、まるで現実世界で撮影された画像に含まれるノイズのようなもので、モデルがノイズを含む画像にも対応できるよう学習を促します。結果として、このランダム性こそが、モデルの性能向上に貢献する重要な要素となっています。
| 手法 | 切り抜き方法 | 塗りつぶし | 多様性 | 効果 |
|---|---|---|---|---|
| カットアウト | 画像内から四角い領域をランダムに選択 | 事前に決めた一定の色(例:黒、灰色)で塗りつぶす | 限定的 | 画像情報の一部欠損 |
| ランダム消去 | 画像内から四角い領域をランダムに選択 | 領域内の各画素にランダムな値を割り当て | 高 | ノイズ付加、モデルの性能向上 |
ノイズとしての効果

模様や画像に不要な情報が混ざってしまうことを、私たちは邪魔な雑音と感じます。この邪魔な情報を、専門用語では雑音と呼びます。しかし、この雑音をうまく使うことで、人工知能の学習能力を高めることが出来るのです。ランダム消去という技術は、画像の一部分をランダムに四角形で隠して、人工知能に学習させます。この隠された部分は、人工知能にとっては雑音のようなものです。人工知能は、一部分が隠された不完全な画像を学習することで、隠された部分を推測する能力を身につけます。まるで、一部分が隠れた絵を見て、全体像を想像するようなものです。この学習を通して、人工知能は、多少情報が欠けていたり、邪魔な情報が混ざっていても、全体像を正しく認識する能力を獲得します。この訓練方法は、現実世界の問題を解く上でとても重要です。現実世界では、写真はいつも完璧に見えるとは限りません。例えば、レンズにゴミが付着していたり、霧がかかっていたり、一部分が影になっていたりするかもしれません。ランダム消去で学習した人工知能は、このような不完全な画像でも正しく認識できるようになります。まるで、多少の傷があっても、それが何の絵なのか理解できる人間のように。このように、ランダム消去は、人工知能に雑音への耐性を高める効果があり、より現実世界の問題に強い人工知能を育てる上で、重要な役割を果たします。人工知能は、雑音の中から本質を見抜く目を養うことで、より賢く、より頼りになる存在へと成長していくのです。
実装の容易さ

画像認識の分野では、学習に用いる画像データを加工して量を増やす手法が盛んに研究されています。この手法は、データ拡張と呼ばれ、認識精度を高めるための重要な技術となっています。数あるデータ拡張の手法の中でも、ランダム消去は実装の容易さという点で特に優れています。
ランダム消去は、その名前の通り、画像の一部分をランダムに消去するというシンプルな手法です。この単純さが、実装の容易さに繋がっています。画像処理に広く利用されている既存の道具を使えば、複雑な手順を踏むことなく容易にプログラムに組み込むことができます。専門的な知識がなくても理解しやすいアルゴリズムであるため、深層学習の初心者にとって最初のデータ拡張手法として最適と言えるでしょう。
他のデータ拡張の手法の中には、画像を回転させたり、歪ませたり、色を変えたりするものもありますが、これらはランダム消去に比べて複雑な計算を必要とする場合が多いです。そのため、プログラムの実装に時間がかかったり、計算に多くの資源が必要となることがあります。一方、ランダム消去は計算処理が軽いので、学習時間の増加も抑えられます。限られた計算資源の中で効率的に学習を進める必要がある場合、ランダム消去は非常に有効な手段となります。
さらに、ランダム消去は僅かなプログラム修正で大きな効果を発揮する点も魅力です。少しの変更で画像認識の精度向上が期待できるため、費用対効果の高い手法と言えるでしょう。画像認識の課題に取り組む際には、まずランダム消去を試してみることを強くお勧めします。
| 手法 | メリット | デメリット |
|---|---|---|
| ランダム消去 | 実装が容易 計算処理が軽い 学習時間の増加を抑えられる 費用対効果が高い |
– |
| 回転、歪み、色変更など | – | ランダム消去に比べて複雑な計算が必要 プログラムの実装に時間がかかる 計算に多くの資源が必要 |