強化学習におけるActor-Critic:行動と評価の協調

AIを知りたい
先生、「アクター・クリティック」って難しくてよくわからないです。簡単に教えてもらえますか?

AIエンジニア
そうだね、難しいよね。「アクター・クリティック」は、簡単に言うと、行動する人と評価する人が組んで、より良い行動を見つける方法だよ。行動する人を「アクター」、評価する人を「クリティック」と呼ぶんだ。
AIを知りたい
行動する人と評価する人…どういうことですか?
AIエンジニア
例えば、ゲームでキャラクターを動かす場面を考えてみよう。アクターは実際にキャラクターを動かす人で、クリティックはその動きを見て点数をつける人だよ。アクターはクリティックの点数が高い行動をどんどん真似していくことで、上手なプレイができるようになるんだ。
Actor-Criticとは。
『行為者-批評家』という人工知能の用語について説明します。この方法は、価値を基にした考え方と、方策の傾きを基にした考え方を組み合わせたものです。この方法では、行為を行う『行為者』と、行為を評価する『批評家』の2つで構成されています。まず、行為者が方針に基づいて行動を選び、実行します。そして、その行動の結果として得られた状態や報酬を、批評家が環境から観察します。批評家は観察した状態や報酬に基づいて評価を行い、その評価に基づいて行為者が方針を更新していきます。この一連の作業を繰り返すことで学習を進めていきます。
はじめに

強化学習とは、機械がまるで人間のように試行錯誤を通して学習していく方法のことを指します。あたかも迷路の中でゴールを目指すように、機械は様々な行動を試しながら、どの行動が最も良い結果をもたらすかを学んでいきます。この学習の過程で中心的な役割を担うのが「エージェント」と呼ばれる学習主体です。エージェントは周囲の環境と相互作用しながら、最適な行動方針を見つけることを目指します。
このエージェントが効果的に学習するための方法の一つとして、Actor-Criticと呼ばれる手法があります。Actor-Criticは、「行動主体(Actor)」と「評価主体(Critic)」という二つの役割を組み合わせた、いわば二人三脚のような学習方法です。行動主体は、現状に応じてどのような行動をとるべきかを決定する役割を担います。例えば、迷路の中で、今いる場所からどちらの方向に進むべきかを判断します。一方、評価主体は、行動主体がとった行動を評価する役割を担います。例えば、選んだ方向がゴールに近づく良い選択だったのか、それとも遠ざかる悪い選択だったのかを判断します。
行動主体は、評価主体の評価を参考にしながら、自分の行動を修正していきます。良い評価を得られれば、その行動を今後も取るように学習し、逆に悪い評価を得れば、その行動を避けるように学習します。このように、行動主体と評価主体が互いに協力しながら学習を進めることで、エージェントはより効率的に最適な行動戦略を習得できるようになります。このActor-Criticこそが、強化学習における重要な手法の一つであり、様々な場面で活用されています。
行動主体の役割

行動主体は、ある状況において、どのような行動をとるかを決定する役割を担います。これは、例えるなら、将棋を指す人がどの駒をどのように動かすか決めるようなものです。行動主体は、現在の盤面の状態、つまり駒の配置や相手の状況といった情報をもとに、次の一手を決めます。
行動主体の行動の選び方は、方策と呼ばれる確率に基づいています。方策は、それぞれの状況で、どの行動をとる確率が高いかを示したものです。たとえば、ある状況で「駒を前に進める」行動の確率が80%、「駒を横に動かす」行動の確率が20%というように、それぞれの行動に確率が割り当てられます。
行動主体の目的は、より良い結果を得られるように、この方策を調整することです。将棋の例でいえば、勝利につながるような手を打つ確率を高めることが目的となります。行動主体は、批評家からの助言をもとに、方策を更新していきます。批評家は、行動主体がとった行動が良いものだったか、悪いものだったかを評価し、その結果を行動主体に伝えます。行動主体は、この批評家の評価をもとに、どの行動の確率を高くするべきか、どの行動の確率を低くするべきかを学習し、方策を改善していきます。
学習の初期段階では、行動主体はランダムに行動を選択することがあります。これは、様々な行動を試すことで、どの行動が良い結果につながるかを探索するためです。しかし、学習が進むにつれて、批評家からのフィードバックをもとに、最適な行動を選択する確率が高くなっていきます。将棋の例でいえば、最初は様々な手を試しますが、経験を積むにつれて、より良い手を選択できるようになるということです。
評価主体の役割

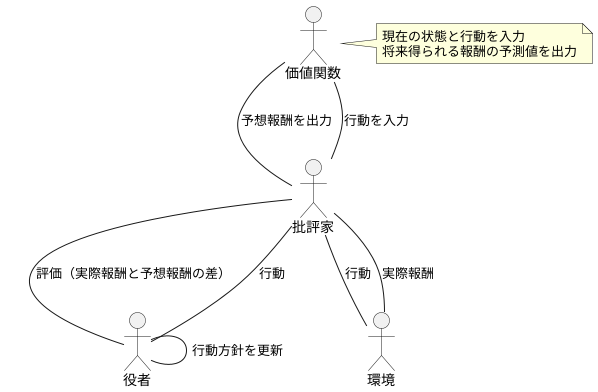
批評家は、評価を行う大切な役割を担います。役者の選んだ行動が良いものだったのか、そうでなかったのかを判断するのが批評家の仕事です。どのように判断するのかというと、価値関数と呼ばれるものを使います。この価値関数は、ある状況で役者が取った行動によって、この後どれだけの報酬が得られるのかを予想する特別な関数です。
批評家は、役者の行動によって実際に得られた報酬と、価値関数が前もって予想した値を比べ合わせます。この比較結果をもとに、役者は自分の行動方針を更新します。例えば、予想よりも報酬が多かった場合は、その行動を強化し、予想よりも報酬が少なかった場合は、その行動を修正します。批評家の評価は、役者がより良い行動を選ぶための道しるべとなるのです。
価値関数についてもう少し詳しく説明すると、これは現在の状態と行動を入力として受け取り、将来得られる報酬の予測値を出力します。将来得られる報酬には、すぐにもらえる報酬だけでなく、ずっと先の未来に得られる報酬も含まれます。これらの報酬を適切に割引して計算することで、長期的な視点で最適な行動を選択できるようにします。
批評家は、客観的な視点から役者の行動を評価し、役者の成長を支援します。役者自身は、自分の行動が良いものだったのか悪いものだったのかを正確に判断できない場合があります。批評家は、専門的な知識と経験に基づいて公正な評価を行い、役者に的確な助言を与えます。批評家の存在は、役者にとって欠かせないものと言えるでしょう。批評家による継続的な評価と指導が、役者の能力向上につながり、より良い成果を生み出す原動力となるのです。
協調による学習

協調学習とは、複数の学習者が互いに協力し合いながら学習を進める手法です。この手法は、まるで師弟関係のように、互いに教え合い、学び合うことで、単独で学習するよりも高い学習効果が期待できます。
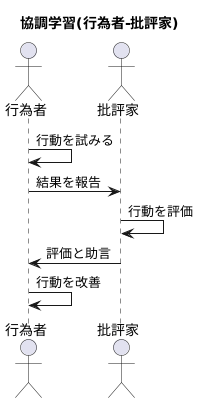
協調学習の中でも、「行為者-批評家」と呼ばれる手法は、特に注目を集めています。この手法では、「行為者」と「批評家」という二つの役割を担う学習者が登場します。
行為者は、様々な行動を試み、その結果を批評家に報告します。批評家は、行為者の行動を評価し、その結果を行為者に伝えます。行為者は、批評家の評価を参考に、自身の行動を改善していきます。
たとえば、迷路を解く場面を想像してみてください。行為者は迷路の中で様々な道を試します。批評家は、行為者が選んだ道がゴールに近いかどうかを評価し、その結果を行為者に伝えます。行為者は、批評家の評価に基づいて、よりゴールに近い道を選び直します。
批評家は、単に行為者の行動を評価するだけでなく、行為者がより良い行動を選択できるように、具体的な助言を与えることもあります。迷路の例では、批評家は「右に曲がると行き止まりになる可能性が高いので、左に曲がった方が良い」といった助言を与えることができます。
このように、行為者と批評家は互いに協力し合いながら学習を進めることで、単独で学習するよりも効率的に最適な行動戦略を学ぶことができます。行為者は批評家の助言によって学習速度を高め、批評家は行為者の行動を通じて評価の精度を高めます。この相互作用こそが、協調学習の真髄と言えるでしょう。
価値関数ベースと方策勾配法の融合

強化学習における価値関数ベースの手法と方策勾配法は、それぞれ異なるアプローチで最適な行動を見つけ出す学習方法です。価値関数ベースの手法は、まず状態や行動の価値を評価する関数を学習します。この関数は、ある状態である行動をとった場合に、将来どれだけの報酬が得られるかを予測します。そして、この予測に基づいて、最も価値の高い行動を選択します。言ってみれば、将来の成果を予測して行動計画を立てるような手法と言えるでしょう。
一方、方策勾配法は、価値関数を介さずに、直接行動を選択する確率を学習します。試行錯誤を通じて、うまくいった行動の確率を高め、失敗した行動の確率を下げることで、最適な行動を見つけ出します。これは、経験から直接行動パターンを学ぶような手法です。
これらの二つの手法を組み合わせたのが、Actor-Criticと呼ばれる手法です。Actor-Criticでは、Actorと呼ばれる部分が方策を学習し、Criticと呼ばれる部分が価値関数を学習します。Actorは、Criticから提供される価値関数の情報を利用して、より効率的に方策を更新します。具体的には、CriticはActorが選択した行動が良いか悪いかを評価し、その評価をフィードバックとしてActorに返します。Actorはこのフィードバックを基に、良い行動の選択確率を高め、悪い行動の選択確率を下げていきます。
このように、Actor-Criticは二つの手法の利点をうまく融合させています。Criticからのフィードバックのおかげで、Actorは試行錯誤だけで学習するよりもずっと効率的に学習できます。また、方策を直接学習するため、価値関数ベースの手法だけでは難しい、複雑な行動も学習できます。つまり、Actor-Criticは、将来予測に基づく計画性と、経験に基づく柔軟性を兼ね備えた学習方法と言えるでしょう。
まとめ

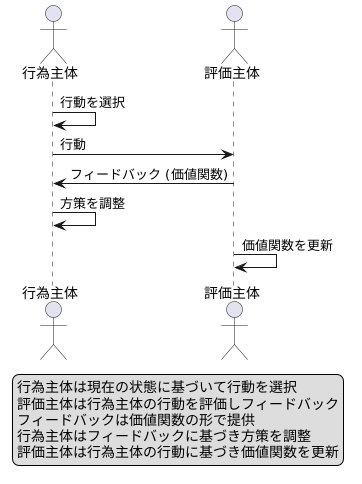
行為主体と評価主体が協力して学習を進める行為主体批評家手法は、強化学習において重要な役割を担っています。この手法は、価値関数に基づく手法と方策勾配法に基づく手法、両方の利点を組み合わせた、より効率的な学習方法です。
行為主体は、現在の状態に基づいて行動を選択します。まるで役者が舞台で役を演じるように、様々な行動を試し、状況に合った最適な行動を見つけ出そうとします。一方、評価主体は、行為主体が選択した行動を評価します。観客のように、行動が良かったのか悪かったのかを判断し、その結果を行為主体にフィードバックします。このフィードバックは、価値関数の形で提供されます。価値関数は、ある状態である行動をとった場合に、将来どれだけの報酬が得られるかを予測する関数です。
評価主体からのフィードバックを受け取った行為主体は、自分の行動を改善していきます。より高い報酬が得られる行動を選択するよう、自身の行動戦略、すなわち方策を調整します。この学習プロセスは、行為主体と評価主体が互いに影響を与え合いながら繰り返されます。行為主体は評価主体のフィードバックに基づいて行動を改善し、評価主体は行為主体の行動に基づいて価値関数を更新します。このようにして、行為主体批評家手法は、最適な行動戦略を学習していきます。
この手法は、様々な分野で応用されています。例えば、ロボットの制御やゲームの思考エンジンなど、複雑な状況下で適切な判断が求められる場面で活用されています。ロボットは、行為主体批評家手法を用いることで、試行錯誤しながら効率的に動作を学習できます。また、ゲームの思考エンジンでは、人間のプレイヤーに匹敵する、あるいは凌駕する高度な戦略を学習することができます。今後、さらに高度な学習手法の開発や、様々な分野への応用が期待される、大変有望な手法と言えるでしょう。