
Actor-Critic:強化学習の新機軸

AIを知りたい
『Actor-Critic』って、なんか俳優と批評家みたいですね。どんな仕組みなんですか?

AIエンジニア
そうだね、名前が面白いよね。Actor-Criticは、まさに俳優と批評家のように、行動する者と評価する者で学習を進める仕組みなんだ。俳優役のActorは、まず試行錯誤しながら行動を選択し、実行する。批評家役のCriticは、その行動の結果を環境から観察し、評価する。
AIを知りたい
なるほど。Actorが行動して、Criticが評価するんですね。それで、その評価はどう活かされるんですか?
AIエンジニア
Criticの評価を元に、Actorは自分の行動の良し悪しを学習し、次にどんな行動をとるかを改善していくんだ。つまり、Criticの評価を受けて、Actorはより良い行動を選択できるようになる。このActorの行動とCriticの評価を繰り返すことで、AIは学習していくんだよ。
Actor-Criticとは。
『行為者-批評家』という人工知能の用語について説明します。これは、価値関数方式と方策勾配法という二つの考え方を組み合わせた方法です。この方法では、行為者と批評家という役割を持つものによって成り立っています。まず、行為者が持つ方針に基づいて行動を選び、実行します。次に、その行動の結果として得られた状態や報酬を、批評家が周りの状況から観察します。そして、批評家は観察した状態と報酬に基づいて評価を行い、その評価に基づいて行為者が方針を更新します。この一連の作業を繰り返すことで学習していきます。
行動主体と評価者の協調

ものの見方や行動の学び方を改善する方法の一つに、強化学習というものがあります。これは、試行錯誤を通じて、どのように行動するのが一番良いかを学ぶ仕組みです。この学習方法の中で、ひときわ注目されているのが行動主体と評価者という二つの役割を組み合わせた、行動主体評価者方式です。これは、従来の方法の良いところを取り入れ、より洗練された学習方法となっています。
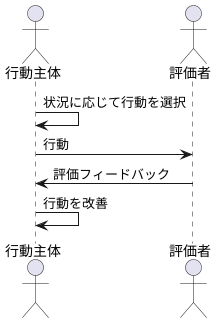
この方式では、文字通り行動主体と評価者が重要な役割を担います。行動主体は、与えられた状況に応じて、どのような行動をとるべきかを決定します。ちょうど、舞台の役者が状況に合わせて演技をするように、行動主体は状況に合った行動を選びます。例えば、迷路の中で、右に行くか左に行くか、どの道を選ぶかを決定します。
一方、評価者は、行動主体が選んだ行動がどれくらい良かったかを評価します。これは、まるで演劇評論家が役者の演技を批評するように、行動の良し悪しを判断します。迷路の例では、選んだ道がゴールに近づく良い選択だったのか、それとも遠ざかる悪い選択だったのかを評価します。そして、その評価結果を行動主体に伝えます。
行動主体は、評価者からのフィードバックを受けて、自分の行動を改善していきます。良い行動は強化され、悪い行動は修正されます。このように、行動主体と評価者が互いに協力しながら学習を進めることで、より効率的に、より良い行動を学ぶことができます。まるで、役者と評論家が協力して、より良い舞台を作り上げていくように、行動主体と評価者は協調して学習を進め、最適な行動を見つけていきます。この協調的な学習こそが、行動主体評価者方式の最大の特徴であり、その効率的な学習効果の根源となっています。
行動主体の役割

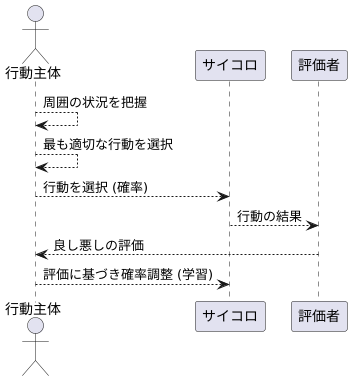
行動主体は、周囲の状況を把握し、最も適切な行動を選ぶ重要な役割を担います。ちょうど、わたしたち人間が周りの状況を見て、どのように行動するか決めるのと同じように、行動主体も与えられた環境の中で、最善の行動を選び出すのです。
行動主体の行動選択は、偶然性に左右される側面を持っています。例えば、サイコロを振って出た目に従って行動を決めるようなものです。ただし、この偶然性は完全にランダムではなく、過去の経験に基づいた計算された偶然性です。評価者から受け取った良し悪しの情報をもとに、行動を選ぶ際のサイコロの目の出やすさが調整されます。
良い結果につながる行動は、選ばれやすくなるように調整されます。サイコロの特定の目がより出やすくなるように、重りを仕込むようなイメージです。反対に、悪い結果につながる行動は、選ばれにくくなるように調整されます。まるで、特定の目がほとんど出ないように、サイコロに細工をするかのようです。
このように、行動の良し悪しを反映して行動選択の傾向を変化させることを学習と呼びます。行動主体は、この学習を通して、環境にうまく適応していく力を高めていきます。まるで、試行錯誤を繰り返しながら、より良い行動を見つけていく職人のようです。
行動主体の行動選択の基準となるのは、状況に応じて変化する柔軟性を備えています。そのため、周りの状況が変化しても、臨機応変に対応し、その時々に最適な行動を選ぶことができるのです。まるで、熟練の棋士が盤面に応じて最善の手を指すように、行動主体も状況に合わせて最適な行動を選び出します。
評価者の役割

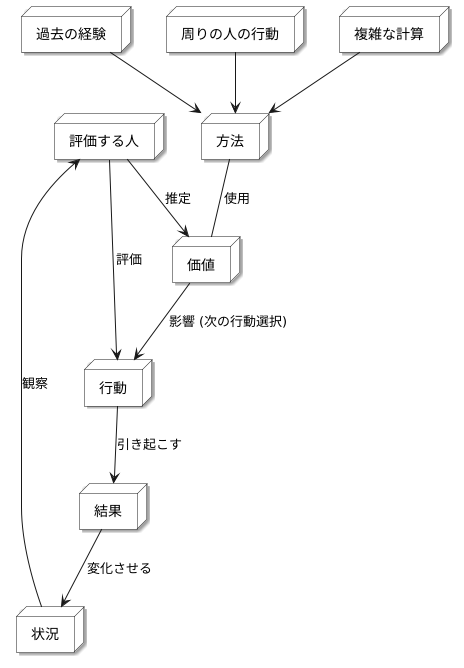
良し悪しを評価する人は、人が何かを行う際に、その行動がどれだけの価値を持つのかを判断する重要な役割を担います。この価値とは、その行動を起こすことで、将来どれだけの見返りが得られるかを予想した値で表されます。たとえば、子供が宿題をきちんと終わらせたら、ご褒美にお菓子をもらえることなどを想像してみてください。この場合、宿題を終わらせるという行動の価値は、お菓子という見返りを得られる期待の大きさで決まります。
評価する人は、人が行動を起こすたびに、その行動がもたらした結果と、その後の状況を注意深く観察します。宿題の例で言えば、子供が宿題を終えたことでお菓子をもらえたのか、そしてその後、嬉しそうにしているのか、それとももっと難しい宿題に挑戦しようとしているのかなどを観察するのです。そして、これらの観察結果に基づいて、行動の価値を推定します。宿題を終えてお菓子をもらえたなら、宿題を終わらせる行動の価値は高いと判断できます。もし宿題を終えた後、もっと難しい問題に挑戦しようとしているなら、その行動はさらに高い価値を持つと評価できるでしょう。
この価値の推定には、様々な方法が使われます。過去の経験から学ぶ方法、周りの人の行動を見て学ぶ方法、あるいは複雑な計算に基づいて予測する方法などがあります。しかし、どんな方法を使うにせよ、将来の見返りを予測し、現在の行動が良いものだったのか、悪いものだったのかを判断することが目的です。まるで未来を見通す水晶玉のように、行動の良し悪しを判断するのです。
評価する人が正確に良し悪しを判断することは、人が効率的に学ぶためにとても重要です。もし評価する人が間違った判断をしてしまうと、人は間違った行動を繰り返してしまう可能性があります。逆に、評価する人が正確な判断を下すことができれば、人はより良い行動を選び、より多くの見返りを得ることができるでしょう。このように、評価する人は、人が成長し、より良い結果を得るための道しるべとなる重要な役割を担っているのです。
学習の進め方

学びを進めるには、行動する人と評価する人の協力が欠かせません。この二つの役割が、まるで役者と批評家のように、互いに影響を与え合いながら、より良い結果へと導きます。
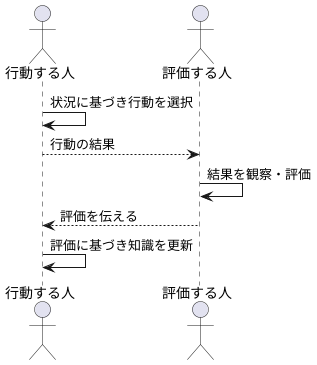
まず、行動する人は、現在の状況を踏まえ、自分が持っている知識に基づいて行動を選びます。この行動は、状況に適した良い行動かもしれませんし、そうでないかもしれません。行動の結果として、どうなるか、何が得られるかを観察するのは、評価する人の役割です。
評価する人は、行動の結果を注意深く観察し、その価値を評価します。この評価は、行動の良し悪しを判断する重要な指標となります。例えば、良い結果が得られたなら高い評価を、悪い結果に終わったなら低い評価を下します。そして、この評価を行動する人に伝えます。
行動する人は、評価する人から受け取った評価を参考に、自分の知識を更新します。高い評価を得た行動は、次に同じような状況に陥った際に、選択される可能性が高くなります。逆に、低い評価を得た行動は、選択される可能性が低くなります。このように、評価に基づいて行動の選択方法を調整することで、より良い行動を選びやすくなります。
この一連の流れ、つまり、行動の選択、結果の観察、評価の伝達、知識の更新を繰り返すことで、行動する人は徐々に最適な行動の選び方を学びます。同時に、評価する人も、より正確な評価を行えるようになります。このように、行動する人と評価する人が互いに協力し合うことで、全体としてより良い結果を生み出すことができるのです。
価値関数と方策勾配法の融合

強化学習とは、試行錯誤を通じて行動を学習する枠組みのことです。その中で、価値関数と方策勾配法という二つの重要な手法があります。価値関数は、ある状態や行動の将来的な報酬の期待値を予測することで、どの行動が最も良いかを判断します。一方、方策勾配法は、行動を決定するための戦略(方策)を直接修正することで、より良い行動を学習します。
これら二つの手法には、それぞれ長所と短所があります。価値関数に基づく手法は学習が安定していますが、方策の更新が間接的であるため、学習速度が遅い場合があります。逆に、方策勾配法は学習速度が速いものの、学習が不安定になりやすいという欠点があります。
そこで、両者の利点を組み合わせた手法がActor-Critic法です。Actor-Critic法は、例えるならば先生と生徒の関係のようなものです。生徒役の行動主体(Actor)は、方策に基づいて行動を選択します。そして、先生役の評価者(Critic)は、その行動の価値を評価し、行動主体にフィードバックします。このフィードバックをもとに、行動主体は方策を修正し、より良い行動を学習していきます。
評価者は価値関数を用いて行動の価値を推定し、行動主体は方策勾配法を用いて方策を更新します。具体的には、評価者が現在の状態と行動に対する価値を予測し、その予測値と実際に得られた報酬との差を計算します。この差が大きいほど、行動主体の行動は改善の余地が大きいことを意味します。行動主体はこの差を基に方策を調整し、より良い行動を選択できるように学習します。このように、Actor-Critic法は価値関数の安定性と方策勾配法の効率性を兼ね備えた、強力な学習手法と言えます。
今後の展望

行為者批評家法は、機械学習の中でも特に注目されている強化学習における重要な手法として、幅広い分野での活用が期待されています。この手法は、試行錯誤を通じて学習を行うという強化学習の特徴を活かしつつ、より効率的に学習を進めることができるという利点を持っています。
具体的には、ロボットの制御、ゲームにおける人工知能、自動車の自動運転など、複雑な判断が求められる分野において、行為者批評家法は大きな可能性を秘めています。今後の研究によって、学習手順の改良や、より複雑な環境への対応などが進めば、その活用範囲はさらに広がっていくと考えられます。
例えば、ロボットの制御においては、これまで以上に複雑な動作の学習や、周りの状況変化への対応力の向上などが期待されます。これにより、様々な作業をこなせるより高度なロボットの開発につながるでしょう。また、ゲームにおける人工知能においては、より高度な戦略の学習や、人間との対戦における成績向上が期待されます。これにより、より人間に近い思考力を持った人工知能の開発が促進されるでしょう。
さらに、自動車の自動運転においては、より安全で効率的な運転の実現が期待されます。これにより、交通事故の減少や交通渋滞の緩和といった、社会全体への貢献も期待できます。このように、行為者批評家法は、様々な分野で革新をもたらす可能性を秘めた、注目すべき技術と言えるでしょう。今後の発展に大いに期待が寄せられています。
| 分野 | 期待される効果 |
|---|---|
| ロボットの制御 | 複雑な動作の学習、状況変化への対応力の向上、高度なロボットの開発 |
| ゲームにおける人工知能 | 高度な戦略の学習、人間との対戦における成績向上、人間に近い思考力を持ったAIの開発 |
| 自動車の自動運転 | 安全で効率的な運転の実現、交通事故の減少、交通渋滞の緩和 |