
データマイニングの成功指標:CRISP-DM

AIを知りたい
先生、『CRISP-DM』って、どういう意味ですか?

AIエンジニア
『CRISP-DM』は、『色々な業界で使えるデータから大切なものを探し出すためのやり方』の略だよ。手順をまとめたものと考えていいでしょう。
AIを知りたい
手順をまとめたもの、ですか?どんな手順があるんですか?
AIエンジニア
例えば、まず何を調べたいかを決めて、次に必要なデータを集める。それからデータを整理して、分析して、最後に結果をまとめる、といった手順があるよ。もっと詳しく知りたい場合は、また質問にお答えします。
CRISP-DMとは。
データマイニング、つまりデータから価値ある知識を見つけるための方法として広く知られている『CRISP-DM』について説明します。CRISP-DMとは、様々な業界で使えるデータマイニングの手順を示したもので、正式には「Crossindustrystandardprocessfordatamining」の略です。
はじめに

近年の情報化社会では、様々な活動を通して日々膨大な量のデータが生み出されています。買い物履歴や位置情報、インターネット上の閲覧履歴など、これらのデータは宝の山と言えるでしょう。しかし、これらのデータをただ集めるだけでは価値を生み出すことはできません。データの中に埋もれた価値ある知見を見つけ出し、活用することが、企業の成長にとって極めて重要になっています。
そこで注目されているのがデータマイニングという手法です。データマイニングとは、大量のデータの中から隠れた規則性やパターン、関係性などを発見する技術のことです。まるで鉱山から貴重な鉱石を掘り出すように、データの山から価値ある情報を抽出します。例えば、顧客の購買履歴を分析することで、顧客の好みやニーズを把握し、効果的な販売戦略を立てることができます。また、機械の稼働データを分析することで、故障の予兆を捉え、未然にトラブルを防ぐことも可能です。
しかし、データマイニングは複雑なプロセスであり、適切な手順を踏まなければ思うような成果を得ることは難しいでしょう。そこで登場するのがCRISP-DM(クロス・インダストリー・スタンダード・プロセス・フォー・データ・マイニング)です。これは、異なる業種の企業でも活用できる、データマイニングの標準的な手順を定めたものです。CRISP-DMは、ビジネス理解、データ理解、データ準備、モデリング、評価、展開という6つの段階から成り立っています。それぞれの段階を順序立てて進めることで、データマイニングプロジェクトを成功に導く確率を高めることができます。まるで地図を頼りに目的地を目指すように、CRISP-DMはデータマイニングの成功への道筋を示してくれるのです。
課題の理解

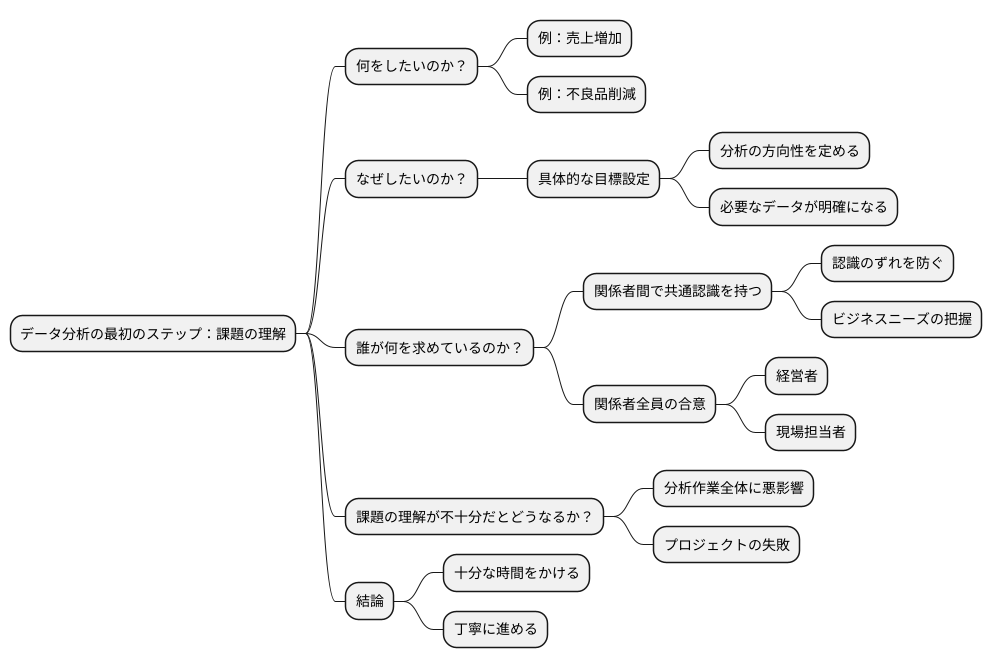
{物事を行うにあたり、まず最初にやるべきことは、何のためにそれを行うのか、その目的をしっかりと理解することです。}データ分析も同様で、データ分析手法のCRISP-DMの最初の段階は、まさにこの点にあたります。まず、分析によって解決したい課題は何か、その課題を解決することでどのような成果を期待しているのかを、はっきりとさせる必要があります。
例えば、お店の売上を伸ばしたい場合、顧客の購買行動を分析することで、より効果的な販売促進活動につなげることが期待できます。あるいは、工場で作られる製品の不良品を減らしたいのであれば、製造工程を分析し、不良品の発生原因を探ることができます。このように、具体的な目標を設定することで、分析の進め方や、どのようなデータを集めるべきかが明確になります。漠然と「データを分析してみよう」と考えているだけでは、成果を上げることは難しいでしょう。
課題を理解する上で大切なのは、関係者全員が同じ認識を持っていることです。例えば、経営者は売上増加を期待しているのに、現場担当者は顧客満足度向上を目標としていると、分析の方向性がずれてしまいます。このような食い違いを防ぐため、関係者間で綿密な話し合いを行い、共通の認識を持つことが重要です。お互いの考えを共有し、ビジネスとしての真のニーズを正しく把握することで、初めて効果的なデータ分析が可能になります。
この最初の段階で、課題の理解が不十分であったり、関係者間で認識のずれが生じていると、その後の分析作業全体に悪影響を及ぼし、最終的にプロジェクトが失敗に終わる可能性も出てきます。だからこそ、最初の段階である課題の理解には、十分な時間をかけて、丁寧に進めていく必要があるのです。
データの理解

事業で抱える問題を明らかにした後は、その問題を分析するために必要な情報を集め、それを深く理解する段階に進みます。どのような情報が必要なのか、どこからその情報を集めるのか、集めた情報の質はどうかといった点を、まず確認します。情報の形式(例えば数値か、それとも文字か)や、情報に欠けている部分がないか、情報の正確さはどの程度かなどを評価します。そして、分析に使いやすい形に情報を整える作業が必要になることもあります。
集めた情報の特性を正しく理解することで、分析方法を適切に選び、確かな結果を得ることができます。また、情報の制約や隠れた問題点も把握しておくことが大切です。例えば、情報の収集期間が短い場合や、特定の傾向に偏った情報しかない場合には、分析結果を解釈する際に注意が必要になります。情報の量や種類が不足している場合は、追加の情報収集や他の情報源の活用を検討する必要があるかもしれません。
情報の質は分析結果の信頼性に直結します。情報の正確さや網羅性を確認するために、情報の出典元を確認したり、複数の情報源を比較したりする作業が重要になります。情報の欠損や偏りがある場合は、その影響を分析結果にどのように反映させるかを考える必要があります。場合によっては、欠損値を補完したり、偏りを調整するための統計的な処理が必要になることもあります。
このように、情報を集めて理解する段階は、その後の分析作業の土台となる重要なプロセスです。時間をかけて丁寧に情報を吟味し、分析に適した状態に整えることで、より正確で意味のある分析結果を得ることが可能になります。
| 段階 | 内容 | 注意点 |
|---|---|---|
| 情報収集 | 問題分析に必要な情報を集める。情報の形式、欠損、正確さを評価する。分析しやすい形に情報を整える。 | 情報の質、情報の制約や隠れた問題点を把握する。情報の収集期間、特定の傾向への偏り、情報の量と種類に注意。 |
| 情報理解 | 集めた情報の特性を理解する。情報の制約や隠れた問題点を把握する。 | 情報の収集期間が短い場合、特定の傾向に偏った情報しかない場合、情報の量や種類が不足している場合に注意が必要。追加の情報収集や他の情報源の活用を検討する。 |
| 情報の質の確認 | 情報の質は分析結果の信頼性に直結する。情報の正確さや網羅性を確認する。情報の出典元を確認、複数の情報源を比較する。 | 情報の欠損や偏りがある場合は、その影響を分析結果にどのように反映させるかを考える。欠損値を補完、偏りを調整するための統計的な処理が必要になる場合もある。 |
データの準備

データ分析を行う上で、土台となるのがデータの準備です。どんなに優れた分析手法を用いても、質の低いデータを使っていては意味のある結果は得られません。データ準備は、家を建てる時の基礎工事に例えることができます。基礎工事がしっかりしていなければ、家は傾いてしまいます。同様に、データ準備が不十分だと、分析結果の信頼性が揺らいでしまいます。
まず、集めたデータをじっくりと観察し、どんな情報が含まれているのか、データの型はどうなっているのか、欠損値や異常値がないかなどを調べます。データに詳しい人であれば、集計値やグラフを作成することで、データの全体像を把握しやすくなります。
次に、分析の目的に合わせてデータを整えます。不要なデータは取り除き、必要なデータだけを選び出します。複数のデータがある場合は、共通の項目で結合し、一つのデータにまとめます。日付や時刻の形式を統一したり、数値データの単位を揃えたりすることも重要です。
データの欠損値への対応も欠かせません。欠損値が多いと、分析結果に偏りが生じる可能性があります。欠損値を平均値や中央値で補完したり、欠損値を含むデータを除外したりするなど、状況に応じて適切な方法を選びます。また、極端に大きい値や小さい値といった外れ値も、分析結果に影響を与えることがあります。外れ値は本当に異常な値なのか、それとも測定誤差なのかを慎重に見極め、必要に応じて修正または削除します。
さらに、データのばらつきを調整するために、正規化などの処理を行うこともあります。例えば、異なる尺度で測定されたデータを比較する際に、正規化を行うことで、尺度の違いによる影響を減らすことができます。
データ準備は、データ分析全体の7割から8割の時間を占めることもあります。地道で大変な作業ですが、分析結果の精度を左右する重要な工程です。焦らず丁寧に作業を進めることで、より信頼性の高い分析結果を得ることが可能になります。
モデル構築

集めた情報を基に、目的に合った計算方法を選び、予測の枠組みを作ります。計算方法は、統計的な分析や、機械学習、深層学習など、様々なものがあります。それぞれの計算方法には得意な事柄や不得意な事柄があるので、取り組むべき課題に対して最適な方法を選ぶことが大切です。例えば、過去の売上データから将来の売上を予測したい場合は、時系列分析という統計的な方法が適しているかもしれません。また、画像から特定の物体を識別したい場合は、深層学習の一種である畳み込みニューラルネットワークが有効です。
予測の枠組みを作る際には、様々な設定値を調整する必要があります。この設定値は、計算方法によって異なります。例えば、深層学習では、学習の速さや、予測の複雑さを調整する必要があります。最適な設定値を見つけるためには、何度も試行錯誤を繰り返す必要があり、根気のいる作業です。設定値を調整しながら、予測の枠組みの正確さを評価します。例えば、過去のデータを使って予測を行い、実際の結果とどれくらい合っているかを調べます。もし予測の正確さが低い場合は、設定値を再度調整したり、計算方法自体を見直したりする必要があります。
このモデル構築の段階では、データ分析の専門家の知識や経験が非常に重要です。専門家は、様々な計算方法の特性を理解しており、課題に最適な方法を選択できます。また、設定値の調整や、予測の正確さの評価についても、豊富な経験に基づいた的確な判断ができます。専門家の助言を得ながらモデル構築を行うことで、より精度の高い予測の枠組みを作ることが可能になります。
| 段階 | 内容 | 方法 | ポイント |
|---|---|---|---|
| 計算方法の選択 | 目的に合った計算方法を選ぶ | 統計分析、機械学習、深層学習など | 計算方法の得意・不得意を考慮し、課題に対して最適な方法を選択 |
| 予測の枠組み作成 | 様々な設定値を調整 | 計算方法によって異なる | 学習の速さ、予測の複雑さなど、試行錯誤が必要 |
| 予測の正確さを評価 | 過去のデータを使って予測を行い、実際とのずれを調べる | 正確さが低い場合は設定値や計算方法を見直す | |
| モデル構築 | データ分析の専門家の知識や経験を活用 | 専門家の助言 | 専門家による計算方法の選択、設定値調整、評価で精度の高い予測が可能 |
評価

作り上げた予測の仕組みを、仕事で使えるものかどうかを様々な角度から詳しく調べます。単に予測の正確さだけでなく、その仕組みがどれくらい分かりやすいか、どれくらい安定して使えるのかなども大切な点です。具体的には、まず予測の仕組みが、目指していた通りの成果を出せているか、仕事の目標に合っているかを確かめます。例えば、商品の売れ行きを予測する仕組みを作った場合、実際に売れた数と予測した数の差がどれくらいあるか、その差が許容範囲内かどうかを調べます。また、売れ行きが大きく外れた場合、なぜ外れたのか、その理由が分かるかどうかも重要です。理由が分かれば、予測の仕組みをさらに良くすることができます。
予測の正確さを調べるには、実際に起きた結果と予測した結果を比べる方法が一般的です。二つの結果がどれくらい近いかを示す数値を計算することで、予測の仕組みの良し悪しを判断します。この数値が高いほど、予測の精度は高いと言えます。しかし、数値だけを見て判断するのではなく、仕事の内容や目的も考慮する必要があります。例えば、病気の診断のように、少しの誤りも許されない場合には、非常に高い精度が求められます。一方、商品の売れ行き予測のように、多少の誤差が許容される場合には、そこまでの精度は必要ありません。
さらに、予測の仕組みが分かりやすいことも重要です。複雑な仕組みでは、なぜそのような予測になったのかを理解することが難しく、改善点を見つけるのが困難になります。また、予測の仕組みが安定しているかどうかも確認する必要があります。データが少し変わっただけで予測結果が大きく変わってしまうようでは、安心して使うことができません。安定した予測の仕組みは、常に一定の精度で予測を行うことができます。
もし、予測の仕組みが期待通りの成果を上げていない場合には、仕組みを作り直したり、予測に使うデータを集め直したりする必要があります。場合によっては、そもそもの仕事の目標設定を見直す必要があるかもしれません。このように、予測の仕組みを評価する段階では、仕事の目的を理解する力と、データを読み解く力の両方が必要になります。常に両方の視点を持ちながら、仕事にとって本当に役立つ予測の仕組みを作ることが大切です。
| 評価項目 | 評価基準 | 具体例 |
|---|---|---|
| 予測精度 | 実績値と予測値の差、許容範囲内か、誤差の理由がわかるか | 商品の売れ行き予測:実際の売上数と予測数の差、誤差の理由の分析 |
| 予測精度の数値評価 | 実績値と予測値の近さを示す数値、仕事の内容や目的を考慮 | 病気の診断:高い精度が必須、商品の売れ行き予測:多少の誤差は許容 |
| 予測の仕組みの分かりやすさ | 予測理由の理解のしやすさ、改善点の見つけやすさ | 複雑な仕組みは理解・改善が困難 |
| 予測の安定性 | データの変化に対する予測結果の変動の大きさ | データが少し変わっただけで予測結果が大きく変わるのは不安定 |
展開

ビジネスにおける価値を生み出すためには、精緻に作り上げた予測モデルを実際に活用することが重要です。この工程を展開と呼びます。展開工程では、作成したモデルを様々な形で実用化します。例えば、分析結果を分かりやすくまとめた報告書を作成し、関係者に伝えることで、意思決定の材料として役立てることができます。また、既存のシステムにモデルを組み込むことで、自動化や効率化を実現することも可能です。
モデルをシステムに組み込む場合、様々な方法があります。例えば、顧客の購買行動を予測するモデルを開発した場合、そのモデルを販売管理システムに組み込むことで、顧客一人ひとりに合わせたお勧め商品を自動的に表示するといった機能を実現できます。他にも、不正検知モデルをセキュリティシステムに組み込むことで、リアルタイムで不正アクセスを監視し、迅速な対応を可能にするといった活用例も考えられます。
展開後も、モデルの性能を継続的に監視することが不可欠です。現実のビジネス環境は常に変化するため、時間の経過とともにモデルの精度が低下する可能性があります。そのため、定期的にモデルの予測結果と実際の結果を比較し、予測精度が落ちていないかを確認する必要があります。もし精度が低下している場合は、モデルの再学習やパラメータ調整といった改善策を講じる必要があります。場合によっては、データ収集方法の見直しや、新たな変数の追加といった根本的な修正が必要になることもあります。
このように、展開は一度で完了する工程ではなく、継続的な改善が必要な工程です。このサイクルを繰り返すことで、モデルの精度を維持・向上させ、ビジネスへの貢献度を高めていくことができます。そして、得られた知見を次の分析に活かすことで、更なる価値を創造していくことが重要です。