
人間フィードバックで進化するAI

AIを知りたい
先生、「RLHF」ってなんですか?難しそうでよくわからないです。

AIエンジニア
RLHFはね、人間がAIに教えてより賢くしていく方法の一つだよ。AIにたくさん問題を解かせて、その答えに対して人間が「これは良い答え」「これは悪い答え」って評価していくんだ。AIは人間の評価を参考にしながら、もっと良い答えを出せるように学習していくんだよ。
AIを知りたい
人間が評価するんですね!でも、どうやってAIは人間の評価を理解するんですか?
AIエンジニア
良い質問だね。AIは、たくさんの評価データから「良い答え」と「悪い答え」の特徴を学ぶんだ。例えば、先生が良い答えに○をつけて、悪い答えに×をつけたとしよう。AIは、○のついた答えには共通の特徴、×のついた答えには共通の特徴があると理解して、次に問題を解くときに○の特徴を持つ答えを出そうとするんだよ。
RLHFとは。
「人工知能に関わる言葉、『人間からの反応を基にした強化学習』について説明します。これは、人工知能が人の思い通りに動くように学習させる方法です。人工知能の出した答えに対して、人が評価や修正を加えることで、さらに学習を進めます。普通の微調整の後に行われ、これら2つを合わせて、広い意味での微調整として扱われることがよくあります。具体的な方法は主に3段階あります。まず最初の段階では、質問とそれに対する模範解答の組を使って、教師あり学習を行います。次の段階では、人工知能に質問を投げかけ、複数の答えを出させます。そして、人がそれらの答えを良いものから順に並べます。この並び順をもとに、報酬モデルを学習させます。最後の段階では、最初の段階と二番目の段階で得られた情報を使って、強化学習を行います。
人間からの助言で学習

近ごろの技術革新で、人工知能は驚くほどの進歩を遂げています。しかし、私たちの思い描いた通りに動いてもらうには、まだ越えなければならない壁があります。そこで今、熱い視線を浴びているのが「人間からの助言で学ぶ強化学習」という手法です。これは、まるで師匠が弟子に教え込むように、人間の意見を聞きながら人工知能が育っていく学習方法です。
これまでの機械学習では、たくさんの情報を人工知能に与えることで学習させていました。しかし、この新しい学習方法では、人工知能が出した答えに対して、人間が直接評価を下します。そして、その評価を元に人工知能はさらに学習を深めていきます。この点が、従来の方法とは大きく異なっています。
たとえば、人工知能に文章を書いてもらう場面を考えてみましょう。従来の方法では、大量の文章データを読み込ませることで文章の書き方を学習させていました。しかし、私たちが本当に求めているのは、ただ文法的に正しい文章ではなく、読みやすく、心に響く文章です。そこで、この新しい学習方法では、人工知能が書いた文章に対して、人間が「分かりやすい」「面白くない」といった評価を付けます。人工知能は、これらの評価をもとに、どのような文章を書けば人間に喜ばれるのかを学んでいきます。
このように、人間からの助言を取り入れることで、人工知能は私たちの価値観や微妙なニュアンスをより深く理解し、より人間らしい振る舞いをすることが期待されています。まるで、熟練の職人が弟子に技術を伝えるように、私たち人間が人工知能を育て、共に成長していく未来が見えてきます。この技術がさらに発展すれば、私たちの生活はより豊かで便利なものになるでしょう。
| 項目 | 従来の機械学習 | 人間からの助言で学ぶ強化学習 |
|---|---|---|
| 学習方法 | 大量のデータを読み込ませて学習 | 人工知能の出力に対して人間が評価を下し、その評価に基づいて学習 |
| データの種類 | 大量のデータ | 人間からの評価 |
| 例:文章生成 | 大量の文章データを読み込み、文法的に正しい文章を作成 | 人間が「分かりやすい」「面白くない」などの評価を付け、人間に喜ばれる文章を作成するように学習 |
| 期待される効果 | – | 人間の価値観やニュアンスを理解し、人間らしい振る舞い |
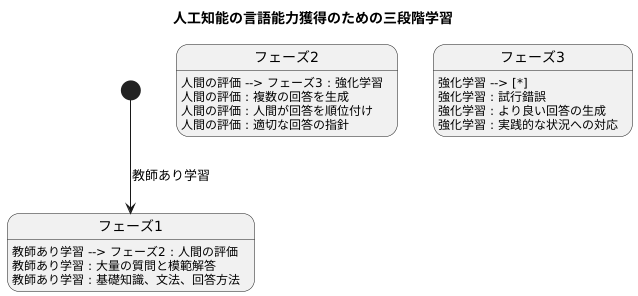
三段階の学習手順

人間が教え込むことで高度な言語能力を獲得する手法の一つに、三段階の学習手順があります。これはまるで人間の学習過程を模倣したかのような方法で、段階的に人工知能を鍛え上げます。
最初の段階は、教師あり学習です。大量の質問と模範解答の組み合わせを用意し、人工知能に学習させます。これは人間で言うなら、教科書を使って基礎知識を学ぶ段階に当たります。様々な分野の質問と模範解答を学ぶことで、言葉の持つ意味や文法、更には質問への適切な回答方法といった基本的な能力を身につけます。この段階が、その後の学習の土台となる重要なステップです。
次の段階は、人間の評価を取り入れるステップです。人工知能に同じ質問に対して複数の回答を生成させ、人間がそれらの回答を良いものから悪いものへと順位付けします。まるで生徒が書いた答案を先生が添削するように、どの回答がより適切で、どの回答が不適切なのかを人間が判断します。人工知能はこの添削結果を通して、より良い回答を生成するための指針を学びます。単に正解を覚えるだけでなく、人間の感性や価値観に合わせた回答を生成する能力を磨く、重要な段階と言えます。
最後の段階は、強化学習です。これまでの二つのステップで得られた知識と人間の評価を基に、人工知能は試行錯誤を繰り返しながら学習を進めます。ちょうどスポーツ選手が実践練習を通して技術を向上させるように、より良い、つまり人間にとってより望ましい回答を生成するように学習します。この段階では、前の二つの段階で学んだことを土台としつつ、より実践的な状況で最適な回答を導き出す能力を磨いていきます。このように、三段階の学習手順を通して、人工知能は人間と自然な言葉で対話できる高度な能力を獲得していくのです。
広義の調整における位置づけ

人工知能のモデルを鍛える際に、よく『微調整』という言葉を耳にします。これは、既に学習を終えたモデルに、特定の仕事に合うように追加の学習をさせることです。この微調整の中に、『人間からの反応に基づく強化学習』というものがあります。これは、普通の微調整の後に行われることが一般的です。これらの二つの段階を合わせて、広い意味での微調整と考える場合も増えてきました。
普通の微調整では、データに基づいてモデルの細かい部分を調整します。例えば、大量の画像データを使って、猫を認識する精度を高めるといった具合です。この方法では、データに含まれる情報をもとに、モデルが自動的に調整を行います。一方、『人間からの反応に基づく強化学習』では、人間が直接評価を行います。具体的には、モデルが出した結果に対して、人間が良いか悪いかを判断し、その評価を基にモデルを調整します。例えば、文章を要約するモデルの場合、人間が複数の要約を比較し、最も良いものを選びます。そして、その選択結果をモデルにフィードバックすることで、より人間の好みに合った要約を出力できるように学習させます。
このように、『人間からの反応に基づく強化学習』は、人間からの直接的な評価に基づいて調整を行うため、より人間の意図に沿った結果が得られると考えられています。普通の微調整は、データの偏りやノイズの影響を受けやすいのに対し、『人間からの反応に基づく強化学習』は、人間の価値観や判断基準を反映させることができるため、より高度なタスクや、人間の感性が必要なタスクに適しています。例えば、文章の生成や翻訳、質疑応答など、より自然で人間らしい出力が求められる場面で効果を発揮します。近年、人工知能技術の進化に伴い、人間と人工知能の協調がますます重要になってきています。『人間からの反応に基づく強化学習』は、まさに人間と人工知能の協調を実現するための重要な技術の一つと言えるでしょう。
| 項目 | 普通の微調整 | 人間からの反応に基づく強化学習 |
|---|---|---|
| 定義 | 既に学習を終えたモデルに、特定の仕事に合うように追加の学習をさせること | 普通の微調整の後、人間が評価を行い、そのフィードバックに基づいてモデルを調整する強化学習 |
| 調整方法 | データに基づいてモデルを自動的に調整 | 人間が結果を評価し、その評価に基づいてモデルを調整 |
| 例 | 大量の画像データを使って、猫を認識する精度を高める | 文章要約モデルで、人間が複数の要約から最適なものを選び、モデルにフィードバックする |
| 利点 | データに基づいて効率的に学習可能 | 人間の意図や価値観を反映した結果を得られる |
| 欠点 | データの偏りやノイズの影響を受けやすい | 人間の評価コストが必要 |
| 適したタスク | 画像認識など、データに基づいて客観的に評価できるタスク | 文章生成、翻訳、質疑応答など、人間の感性が必要なタスク |
人間らしさへの挑戦

機械学習という技術は急速に進歩していますが、生成される文章が時に人間が期待するものとは異なることがあります。まるで人間が書いたような、自然で思いやりのある文章を作り出すためには、人間の意図や価値観を機械に理解させる必要があります。これを目指す技術の一つが人間からのフィードバックによる強化学習(RLHF)です。
従来の機械学習では、大量のデータからパターンを学ぶことで文章を生成していました。しかし、この方法ではデータに含まれる偏見や差別も一緒に学習してしまう危険性がありました。例えば、過去のデータに男性医師が多いという情報が含まれていた場合、AIは医師を男性として認識し、女性医師について適切な文章を生成できない可能性があります。このような問題を解決するために、RLHFは人間のフィードバックを学習に取り入れています。具体的には、人間がAIの出力に対して「良い」「悪い」といった評価を与え、AIはその評価に基づいて学習を進めます。
RLHFは、単に正しい情報を伝えるだけでなく、人間の倫理観や道徳観をAIに反映させることを目指しています。例えば、ある出来事について複数の解釈が可能な場合、人間はどの解釈がより適切かを判断できます。RLHFを用いることで、AIも人間と同じように適切な解釈を選択できるようになることが期待されています。これは簡単なことではありません。人間の倫理観や道徳観は複雑で、常に変化する可能性があります。しかし、AIが人間社会で安全に役立つためには、これらの要素をAIに組み込むことが不可欠です。RLHFは、この困難な課題に挑戦するための、重要な一歩と言えるでしょう。
RLHFによって、AIは人間のパートナーとして、より複雑な仕事や創造的な活動にも貢献できるようになると考えられます。文章作成だけでなく、様々な分野での応用が期待されており、私たちの生活をより豊かにしてくれる可能性を秘めています。
| 項目 | 説明 |
|---|---|
| 機械学習の課題 | 生成される文章が人間が期待するものと異なる場合がある。データの偏見や差別を学習する危険性がある。 |
| RLHF (人間からのフィードバックによる強化学習) | 人間のフィードバック(良い/悪い)を学習に取り入れることで、人間の意図や価値観をAIに理解させる技術。 |
| RLHFの目的 | 単に正しい情報を伝えるだけでなく、人間の倫理観や道徳観をAIに反映させる。適切な解釈の選択を可能にする。 |
| RLHFの課題 | 人間の倫理観や道徳観は複雑で変化するため、AIへの反映は容易ではない。 |
| RLHFの将来 | AIが人間のパートナーとして、複雑な仕事や創造的な活動に貢献。様々な分野での応用が期待される。 |
今後の展望と期待

人間と人工知能が協調する未来を実現するため、人工知能の学習手法の一つである「人間からのフィードバックによる強化学習」は、今後の発展に大きな期待が寄せられています。この手法は、従来の方法とは異なり、人間の評価や指示を直接的に学習過程に取り入れることで、より人間らしい振る舞いをする人工知能の実現を目指しています。
現在、この分野では様々な研究開発が活発に行われています。例えば、より質の高いフィードバックを得るための方法や、学習の効率を高めるための新たな計算方法の開発などが精力的に進められています。これらの研究成果によって、人工知能は人間の意図や気持ちをより深く理解し、複雑な状況においても適切な判断や行動ができるようになると期待されています。
また、人間からのフィードバックによる強化学習は、様々な課題解決への応用が期待されています。例えば、医療分野では、患者の状態に合わせて最適な治療方法を提案する人工知能の開発に役立つと考えられています。さらに、教育分野では、生徒一人ひとりの学習状況に合わせた個別指導を行う人工知能の実現にも貢献すると期待されています。
人間と人工知能が共存する社会において、人間からのフィードバックによる強化学習は、人工知能をより人間に寄り添う存在へと進化させるための重要な技術となるでしょう。今後、この技術がさらに発展し、様々な分野で応用されることで、私たちの生活はより豊かで便利なものになることが期待されます。人工知能が人間の良きパートナーとして、様々な課題を共に解決していく未来を目指し、研究開発は今後も続いていくでしょう。
| テーマ | 説明 |
|---|---|
| 人間からのフィードバックによる強化学習 | 人間の評価や指示を学習過程に取り入れ、人間らしい振る舞いをするAIを目指す学習手法。 |
| 研究開発の現状 |
|
| 期待される効果 |
|
| 応用分野 |
|
| 将来展望 | AIが人間の良きパートナーとなり、様々な課題を共に解決。生活はより豊かで便利に。 |