
RLHFによる学習

AIを知りたい
先生、『RLHF』ってなんですか?なんか、AIの学習方法らしいんですけど…

AIエンジニア
いい質問だね。『RLHF』は『人間の反応を強化学習で学習する』っていう意味だよ。人間がAIの出力に対して『良い』『悪い』と評価することで、AIはより良い出力を目指して学習していくんだ。
AIを知りたい
『人間の反応を強化学習で学習する』ですか?難しそうですね…。もう少し具体的に教えてもらえますか?
AIエンジニア
例えば、文章を要約するAIを考えてみよう。AIが作った要約を人間が評価する。良い要約であれば高い点数を、悪い要約であれば低い点数を付ける。AIはこの点数をもとに、より高い点数がもらえる、つまり人間により良い評価をもらえる要約の作り方を学習していくんだよ。
RLHFとは。
人工知能の分野で使われる『強化学習を使って人間からのフィードバックを反映させる学習方法』(英語の頭文字をとってアールエルエイチエフ)について。
はじめに

近ごろ、機械学習、とりわけ深層学習の進歩には目を見張るものがあり、様々な分野で画期的な成果をあげています。この流れのなかで、人の評価を強化学習に取り込む手法である人間フィードバック強化学習(RLHF)が注目を集めています。
従来の強化学習では、何を基準に良し悪しを判断するのかを数値で示す必要がありました。この良し悪しの判断基準を報酬と呼びますが、この報酬を適切に設計するのは非常に難しい作業でした。例えば、文章の良し悪しを評価する場合、文法的な正しさや内容の正確さだけでなく、読みやすさや面白さなど、様々な要素を考慮する必要があります。このような複雑な基準を数値で表現することは容易ではありません。
RLHFは、人の評価を直接利用することで、この報酬設計の難しさを解消しようとする試みです。具体的には、まず人間がいくつかの行動に対して評価を与えます。次に、この評価データを用いて報酬モデルを学習します。この報酬モデルは、人間の評価を予測する機能を持ちます。最後に、学習した報酬モデルを強化学習アルゴリズムに組み込むことで、人間が好ましいと感じる行動を学習させることができます。
RLHFは、従来手法では難しかった複雑なタスクにも適用可能です。例えば、チャットボットの開発において、RLHFを用いることで、より自然で人間らしい会話ができるチャットボットを実現できる可能性があります。また、文章生成タスクにおいても、RLHFを用いることで、より質の高い文章を生成することが期待されます。
RLHFは発展途上の技術ですが、今後、様々な分野への応用が期待されています。人間と機械の協調作業を促進する上で、RLHFは重要な役割を果たす可能性を秘めていると言えるでしょう。
| 項目 | 説明 |
|---|---|
| RLHF (人間フィードバック強化学習) | 人の評価を強化学習に取り込む手法。報酬設計の難しさを解消し、人間が好ましいと感じる行動を学習させる。 |
| 従来の強化学習の課題 | 報酬(良し悪しの判断基準)を数値で設計することが難しい。例えば、文章の評価には文法、内容、読みやすさ、面白さなど様々な要素があり、数値化が困難。 |
| RLHFの仕組み | 1. 人間が行動を評価 2. 評価データで報酬モデルを学習 3. 学習した報酬モデルを強化学習アルゴリズムに組み込み、人間が好ましい行動を学習 |
| RLHFの利点 | 複雑なタスクへの適用が可能。例: ・チャットボット:より自然で人間らしい会話 ・文章生成:より質の高い文章 |
| RLHFの将来性 | 発展途上の技術だが、様々な分野への応用が期待され、人間と機械の協調作業を促進する可能性がある。 |
学習の仕組み

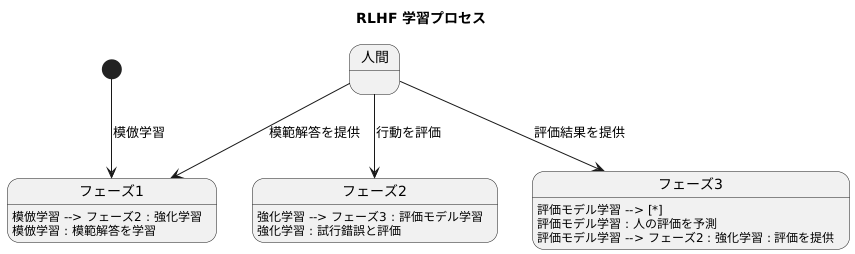
学ぶとは、経験を通して知識や技能を身につけることです。人間が学ぶように、機械も学ぶことができます。その方法の一つに、RLHFと呼ばれる学習方法があります。これは、人の手助けを借りながら、機械がより良い働きができるようにする学習方法です。
RLHFは、大きく分けて三つの段階で学習を進めます。まず初めに、既に人が用意した模範解答のようなものを使って、基本的な振る舞いを学習します。これは、先生が生徒にお手本を見せるようなものです。この段階では、機械はまだ正解が何かを理解しているわけではなく、ただお手本を真似ているだけです。
次に、機械が自ら試行錯誤を繰り返し、より良い行動を見つけ出す段階に入ります。この時、人は機械の行動に対して良し悪しを評価します。ちょうど、先生が生徒の解答を採点するようにです。機械はこの評価を参考に、自分の行動を改善していきます。良い評価を得られる行動は強化され、悪い評価の行動は修正されます。このように、人の評価が機械の学習を導くのです。
最後に、人の評価を予測する別の機械を準備します。これは、先生に代わって生徒の解答を採点する助手を育てるようなものです。この助手は、これまでの先生による評価結果を学習することで、先生と似たような評価をできるように育っていきます。この助手が育つと、先生はすべての生徒の解答を直接採点する必要がなくなり、学習をより速く進めることができます。
このように、RLHFは人の指導と機械の試行錯誤を組み合わせることで、複雑な作業でも優れた成果を出せるように機械を学習させる方法です。
利点

人間が持つ知識や価値観を反映できることが、RLHFと呼ばれる技術の大きな強みです。従来の機械学習では、良し悪しを判断する基準を明確に数値で示す必要がありました。これを報酬関数と呼びますが、人の価値観のように複雑なものを数値化するのは難しく、学習の妨げになっていました。RLHFは、この数値化という難題を回避し、より人間らしい行動を機械に学習させることを可能にします。
例えば、文章を作る分野では、RLHFを使うことで、より自然で人間らしい文章を生成する機械を作ることができます。従来の方法では、文法的に正しくても、どこか不自然な文章が作られることがありました。RLHFを用いることで、言葉の選び方や言い回しなど、数値化が難しい要素も含めて学習させることができるため、より自然な文章が作られるようになります。まるで人が書いたような文章を機械が生成できるようになり、文章作成支援ツールや自動翻訳の質の向上に役立つと考えられます。
また、機械の動きを制御する分野でも、RLHFは期待されています。例えば、ロボットに複雑な作業をさせたい場合、従来の方法では、あらゆる状況を想定した指示をプログラムする必要がありました。しかし、RLHFを使うことで、人間が望む動作を、試行錯誤を通じてロボットに学習させることができます。安全性を重視しながら、効率的な動きを学習させることも可能です。人間にとって危険な作業や、細かい作業をロボットに任せられるようになり、様々な分野での活躍が期待されています。このように、RLHFは様々な分野で応用が期待される、注目すべき技術と言えるでしょう。
| 特徴 | 従来の機械学習 | RLHF | メリット |
|---|---|---|---|
| 良し悪しの基準 | 数値化(報酬関数)が必要 | 数値化を回避 | 複雑な価値観を反映可能 |
| 文章生成 | 不自然な文章 | 自然で人間らしい文章 | 文章作成支援、自動翻訳の質向上 |
| 機械制御 | あらゆる状況を想定したプログラム | 試行錯誤を通じて学習 | 危険な作業、細かい作業の自動化 |
課題

強化学習を用いた人間からのフィードバック学習(略称人間フィードバック強化学習)は、優れた方法である一方、いくつかの問題点も抱えています。まず、人間からの意見を集めるための費用が高いことが挙げられます。質の高い意見を得るには、専門的な知識を持つ人による評価が必要になることがあり、大規模な学習用データを作るには多くの時間と労力が必要です。たとえば、ある特定の分野の専門知識を持つ人材を探し、報酬を支払い、評価作業を依頼するまでには、多くの手続きと費用が発生します。また、評価基準を明確化し、評価者間のばらつきを最小限に抑えるための訓練も必要となるでしょう。
次に、人間からの意見には偏りや誤りが含まれる可能性があります。人はそれぞれ異なる背景や価値観を持つため、同じものを見ても異なる評価をする可能性があります。これは、学習用データに偏りを生じさせ、結果として作られるモデルの性能に悪影響を与える可能性があります。このため、偏りや誤りの影響を少なくするための対策が必要です。たとえば、複数の人から意見を集め、平均値を用いる、あるいは、偏りを補正するためのアルゴリズムを開発するといった対策が考えられます。
さらに、人間フィードバック強化学習による学習は計算量が大きく、大規模なモデルを学習させるには高性能な計算機が必要となります。学習データが大規模になればなるほど、計算量は増加し、学習に必要な時間も長くなります。そのため、最新の計算機や効率的な学習アルゴリズムの開発が不可欠です。これらの問題点は、人間フィードバック強化学習を広く普及させるための大きな障壁となっています。現在、これらの問題を解決するための研究開発が盛んに行われています。より効率的な学習アルゴリズムの開発や、偏りを補正する技術の開発など、今後の進展が期待されます。
| 問題点 | 詳細 | 対策 |
|---|---|---|
| 費用が高い | 専門知識を持つ人材への報酬、評価基準の明確化、評価者訓練等 | – |
| 人間からの意見の偏りや誤り | 異なる背景や価値観による評価のばらつき | 複数人からの意見の平均値利用、偏り補正アルゴリズム開発 |
| 計算量の大きさ | 大規模モデル学習に必要な高性能計算機、学習データ量の増加に伴う計算量の増加 | 最新の計算機や効率的な学習アルゴリズムの開発 |
応用例

人間からの評価を取り入れる強化学習手法、すなわち報酬モデルを人間のフィードバックで学習させる方法(RLHF)は、様々な分野で活用が期待されています。具体的には、人とコンピュータが言葉を交わす仕組みである対話システムにおいては、より自然で、まるで人間と話しているような感覚になる会話文を生成する技術に応用されています。従来の対話システムでは、機械的な応答になりがちでしたが、この手法を用いることで、文脈を理解し、より人間らしい会話の流れを作り出すことが可能になります。
また、文章を作る作業である文章生成タスクにおいても、より独創的で質の高い文章の作成を支援する技術として注目を集めています。例えば、小説や詩、ニュース記事、広告コピーなど、様々な種類の文章生成において、人間の感性や創造性により近い表現力を持つ文章を生成することが期待されます。これは、従来の技術では難しかった、言葉の選び方や表現の微妙なニュアンスを学習できるようになるためです。
さらに、コンピュータ上で遊ぶゲームにおいても、人間の熟練者のように高度な戦略を学ぶ人工知能の開発に応用されています。複雑なルールや状況判断が求められるゲームにおいて、人間の思考プロセスを模倣することで、より高度な戦略を自動的に学習できるようになります。将棋や囲碁のような戦略性の高いゲームだけでなく、様々なコンピュータゲームで人間に匹敵する、あるいは人間を超える人工知能の実現が期待されます。
これらの例は、人間からの評価を取り入れる強化学習手法が持つ可能性のほんの一部です。今後、更なる研究開発が進むことで、想像もしていなかった新たな分野での応用が期待されています。
| 分野 | RLHFの応用 | 従来の課題 | 期待される効果 |
|---|---|---|---|
| 対話システム | より自然で人間らしい会話文を生成 | 機械的な応答になりがち | 文脈を理解し、人間らしい会話の流れを作り出す |
| 文章生成タスク | 独創的で質の高い文章の作成支援 | 言葉の選び方や表現のニュアンスが難しい | 人間の感性や創造性に近い表現力を持つ文章生成 |
| ゲーム | 人間の熟練者のように高度な戦略を学ぶAI開発 | 複雑なルールや状況判断が難しい | 人間に匹敵する、あるいは人間を超えるAIの実現 |
今後の展望

人間からの反応を学習に取り入れる強化学習、すなわち人間フィードバック型強化学習(RLHF)は、発展が始まったばかりの技術ですが、秘めた可能性は計り知れません。今後、様々な分野で活躍が期待されています。現状では、人から教わる際の効率や、偏った考えや誤った情報の影響を少なくする対策が課題となっています。これらの課題を解決するために、活発な研究開発が行われています。
まず、人からの教えをよりスムーズかつ効率的に学習に取り入れる方法が模索されています。より少ない情報で、より多くのことを学ぶことができるようになれば、学習にかかる時間や手間を大幅に削減できます。そして、人から教わる際に含まれる偏見や思い込み、あるいは誤った情報といったノイズを取り除く方法も重要です。これらのノイズは学習の精度を下げてしまうため、ノイズの影響を最小限に抑える技術の開発が求められています。
さらに、RLHFと他の学習方法を組み合わせる研究も進められています。例えば、深層学習や転移学習といった技術と組み合わせることで、より複雑で高度な作業を学習できる可能性があります。深層学習は、人間の脳の仕組みを模倣した学習方法であり、大量のデータから複雑なパターンを学習することができます。また、転移学習は、既に学習した知識を新しい課題に活用する学習方法です。これらの技術とRLHFを組み合わせることで、より効率的かつ高度な学習が実現すると期待されています。
加えて、人からの教えだけでなく、他の情報源からの情報も学習に活用することで、より効果的な学習が可能になるかもしれません。例えば、インターネット上の膨大な情報や、センサーなどから得られるデータなども学習に利用できる可能性があります。これらの多様な情報源を活用することで、より多角的で精度の高い学習が可能になると考えられます。
このように、様々な角度からの研究開発を通して、RLHFは今後ますます発展し、様々な分野で重要な役割を果たしていくことが期待されています。
| 課題 | 解決策 | 関連技術 |
|---|---|---|
| 学習効率 | 少ない情報で多くのことを学ぶ | – |
| 偏見やノイズ | ノイズの影響を最小限に抑える技術 | – |
| 複雑な作業 | RLHFと他学習方法の組み合わせ | 深層学習、転移学習 |
| 多角的な学習 | 多様な情報源を活用 | インターネット、センサーデータ |